光流法:从传统方法到深度学习方法
1 光流法简介
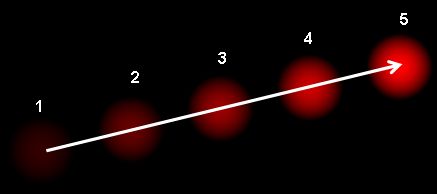
光流(Optical Flow)是指图像中像素灰度值随时间的变化而产生的运动场。 简单来说,它描述了图像中每个像素点的运动速度和方向。 光流法是一种通过分析图像序列中像素灰度值来计算光流的方法。对于图像数据计算出来的光流是一个二维向量场。比如Opencv官方给的示例图,该图中显示了一个连续运动的光点,箭头的方向表示光流的方向,箭头的大小表示光流的大小。有了光流场,我们就可以利用光流场来跟踪图像中的目标物体,就可以进行运动跟踪,目标检测,视频压缩,运动分割,三维重建等。
光流法基于以下基本假设:
亮度恒定:就是同一点随着时间的变化,其亮度不会发生改变。
小运动假设(Small Motion Assumption): 相邻帧之间的运动是微小的,足以进行线性近似。
假设每两帧画面之间的时间间隔为 $\Delta t$,且运动很小,通过泰勒级数展开,有: $$ \begin{aligned} {\displaystyle I(x+\Delta x,y+\Delta y,t+\Delta t)=I(x,y,t)+{\frac {\partial I}{\partial x}}\Delta x+{\frac {\partial I}{\partial y}}\Delta y+{\frac {\partial I}{\partial t}}\Delta t+} R(x,y,t) \end{aligned} $$
其中,$I(x, y, t)$ 表示图像在点 $(x, y)$ 处的灰度值,$t$ 表示时间,$\Delta x$、$\Delta y$ 和 $\Delta t$ 分别表示水平、垂直和时间上的位移,$R(x, y, t)$ 表示泰勒级数展开的高阶项。根据光流法的基本假设,有: $$ I(x+\Delta x,y+\Delta y,t+\Delta t)=I(x,y,t) $$
由于泰勒高阶项趋近于0,直接忽略,则有: $$ {\displaystyle {\frac {\partial I}{\partial x}}\Delta x+{\frac {\partial I}{\partial y}}\Delta y+{\frac {\partial I}{\partial t}}\Delta t=0} $$ 等价为: $$ {\displaystyle {\frac {\partial I}{\partial x}}{\frac {\Delta x}{\Delta t}}+{\frac {\partial I}{\partial y}}{\frac {\Delta y}{\Delta t}}+{\frac {\partial I}{\partial t}}{\frac {\Delta t}{\Delta t}}=0} $$ 其中,$\Delta t$ 表示时间间隔,$\Delta x$ 和 $\Delta y$ 分别表示水平和垂直上的位移。则: $$ {\displaystyle {\frac {\partial I}{\partial x}}V_{x}+{\frac {\partial I}{\partial y}}V_{y}+{\frac {\partial I}{\partial t}}=0} $$ 其中,$V_x$ 和 $V_y$ 分别表示光流在水平和垂直方向上的分量。则我们需要求解的问题为: $$ {\displaystyle I_{x}V_{x}+I_{y}V_{y}=-I_{t}} $$ 简化为: $$ {\displaystyle \nabla I^{T}\cdot {\vec {V}}=-I_{t}} $$
2 传统算法
2.1.1 Lucas-Kanade光流法
Lucas-Kanade 方法是一种广泛使用的光流估计微分方法,由 Bruce D. Lucas 和Takeo Kanade开发。该方法假设光流在所考虑像素的局部邻域中基本恒定,并根据最小二乘准则求解该邻域内所有像素的基本光流方程。 LK光流法基于以下假设:
小运动假设(Small Motion Assumption): 相邻帧之间的运动是微小的,足以进行线性近似。
亮度恒定:就是同一点随着时间的变化,其亮度不会发生改变。
空间一致性:场景中相同表面的相邻点具有相似的运动,并且其投影到图像平面上的距离也比较近。一个场景上邻近的点投影到图像上也是邻近点,且邻近点速度一致。
前两个假设是基于泰勒展开的,是所有传统光流法的基础。根据前两个假设,前面已经推导过需要求解: $$ {\displaystyle \nabla I^{T}\cdot {\vec {V}}=-I_{t}} $$
空间一致性假设(邻域光流相似假设) 针对第三个假设,我们可以假设在一个大小为 $w \times w$ 的窗口内,所有像素点的光流都相同。则有: $$ {\displaystyle {\begin{aligned}I_{x}(q_{1})V_{x}+I_{y}(q_{1})V_{y}&=-I_{t}(q_{1})\I_{x}(q_{2})V_{x}+I_{y}(q_{2})V_{y}&=-I_{t}(q_{2})\&;\ \vdots \I_{x}(q_{n})V_{x}+I_{y}(q_{n})V_{y}&=-I_{t}(q_{n})\end{aligned}}} $$
其中,$q_{1}, q_{2}, \cdots, q_{n}$ 表示窗口内的像素点,$I_{x}(q)$ 和 $I_{y}(q)$ 表示窗口内像素点的梯度,$I_{t}(q)$ 表示窗口内像素点灰度梯度。将该公式表示为矩阵形式为${\displaystyle Av=b}$: $$ {\displaystyle A={\begin{bmatrix}I_{x}(q_{1})&I_{y}(q_{1})\[10pt]I_{x}(q_{2})&I_{y}(q_{2})\[10pt]\vdots &\vdots \[10pt]I_{x}(q_{n})&I_{y}(q_{n})\end{bmatrix}}\quad \quad \quad v={\begin{bmatrix}V_{x}\[10pt]V_{y}\end{bmatrix}}\quad \quad \quad b={\begin{bmatrix}-I_{t}(q_{1})\[10pt]-I_{t}(q_{2})\[10pt]\vdots \[10pt]-I_{t}(q_{n})\end{bmatrix}}} $$
该系统方程组的数量多于未知数的数量,无法直接求解。因此,我们可以使用最小二乘来求解数值解,得到: $$ {\displaystyle v=\left(A^{T}A\right)^{-1}A^{T}b} $$ 其矩阵形式为: $$ {\displaystyle {\begin{bmatrix}V_{x}\[10pt]V_{y}\end{bmatrix}}={\begin{bmatrix}\sum {i}I{x}(q_{i})^{2}&\sum {i}I{x}(q_{i})I_{y}(q_{i})\[10pt]\sum {i}I{y}(q_{i})I_{x}(q_{i})&\sum {i}I{y}(q_{i})^{2}\end{bmatrix}}^{-1}{\begin{bmatrix}-\sum {i}I{x}(q_{i})I_{t}(q_{i})\[10pt]-\sum {i}I{y}(q_{i})I_{t}(q_{i})\end{bmatrix}}} $$
为了方程${\displaystyle A^{T}Av=A^{T}b}$可解,${\displaystyle A^{T}A}$应该是可逆的,或者${\displaystyle A^{T}A}$的特征值满足${\displaystyle \lambda _{1}\geq \lambda _{2}>0}$。为了避免噪音问题,通常${\displaystyle \lambda _{2}}$不能太小。另外,如果${\displaystyle \lambda _{1}/\lambda _{2}}$太大,这意味着点 页${\displaystyle p}$位于边缘,容易导致多孔径问题(即不同方向的光流观察到的结果一致,而无法确认光流的方向)。因此,为了使该方法正常工作,条件是${\displaystyle \lambda _{1}}$和${\displaystyle \lambda _{2}}$足够大且具有相似的量级。这个条件也是角点检测的条件。这项观察表明,通过检查单个图像,可以轻松判断哪个像素适合使用 Lucas-Kanade 方法。 算法改进 LK光流假设相同点在相邻帧画面中移动租足够小,但是在实际场景中很多时候光流是很大的,因此需要对LK光流法进行改进。其中一种改进方法就是引入图像金字塔的多尺度处理。使用图像金字塔改进 LK 光流算法的主要思想是:
解决大位移问题: 传统的 LK 光流算法基于小运动假设,当图像中存在大位移运动时,算法的精度会下降。 通过使用图像金字塔,可以将大位移运动分解为多个小位移运动,从而提高算法的精度。
由粗到精的策略: 首先在金字塔的顶层(低分辨率图像)估计光流,然后在金字塔的下一层(较高分辨率图像)对光流进行细化,以此类推,直到金字塔的底层(原始图像)。 这种由粗到精的策略可以有效地减少计算量,并提高算法的鲁棒性。
基本步骤为:
构建图像金字塔: 对连续的两帧图像分别构建图像金字塔。
初始化光流: 在金字塔的顶层,将光流初始化为零。
由粗到精的光流估计: 从金字塔的顶层开始,逐层向下进行光流估计和细化:
光流估计: 在当前层,使用 LK 光流算法估计光流。
光流上采样: 将当前层的光流上采样到下一层,作为下一层光流的初始值。
图像扭曲 (Warping): 使用当前层的光流对下一帧图像进行扭曲,使得两帧图像更加对齐。
光流细化: 在下一层,使用 LK 光流算法对光流进行细化。
重复步骤 3,直到金字塔的底层。
实践
import cv2
import numpy as np
def visualize_lk_optical_flow(video_path):
"""
使用金字塔 LK 光流算法预览视频的光流场。
Args:
video_path (str): 视频文件的路径。
"""
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"无法打开视频文件: {video_path}")
return
ret, old_frame = cap.read()
if not ret:
print("无法读取视频的第一帧。")
return
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# Shi-Tomasi 角点检测参数
feature_params = dict(maxCorners=100,
qualityLevel=0.3,
minDistance=7,
blockSize=7)
# LK 光流参数
lk_params = dict(winSize=(15, 15),
maxLevel=2,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 创建随机颜色用于绘制轨迹
color = np.random.randint(0, 255, (100, 3))
# 检测 Shi-Tomasi 角点
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
# 确保 p0 的数据类型和形状正确
if p0 is not None:
p0 = np.float32(p0)
# 创建一个 mask 用于绘制光流轨迹
mask = np.zeros_like(old_frame)
while True:
ret, frame = cap.read()
if not ret:
break
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流
if p0 is not None: # 确保有角点可以跟踪
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 选择好的跟踪点
if p1 is not None:
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv2.line(mask, (int(a), int(b)), (int(c), int(d)), color[i].tolist(), 2)
frame = cv2.circle(frame, (int(a), int(b)), 5, color[i].tolist(), -1)
img = cv2.add(frame, mask)
cv2.imshow('LK 光流', img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
# 更新前一帧和跟踪点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
else:
# 如果没有跟踪点,重新检测角点
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
if p0 is not None:
p0 = np.float32(p0)
mask = np.zeros_like(old_frame) # 清空 mask
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
video_path = "B:/Code/TestForLearn/Src/PyTest/ImageProcess/videos/3.mp4" # 替换为你的视频文件路径
visualize_lk_optical_flow(video_path)

2.1.2 Farneback光流法
Farneback光流法不同于LK光流法,其是基于特征点的稠密光流法,其基于图像金字塔和多尺度处理。 稠密光流意味着它为图像中的每个像素都计算一个运动矢量。 Farneback 算法特别之处在于它使用多项式展开来近似图像的局部邻域,从而估计运动。
Farneback 算法的核心思想是使用二次多项式来近似每个像素的局部邻域的亮度分布。 对于图像中的每个像素 (x, y),其邻域的亮度值 I(x, y) 可以用以下二次多项式表示: $$ I(x, y) ≈ x^T * A * x + b^T * x + c $$
$x = [x, y]^T$是像素坐标的向量。
$A$ 是一个 2x2 的矩阵,表示二次项系数。
$b$ 是一个 2x1 的向量,表示一次项系数。
$c$ 是一个标量,表示常数项。
算法通过最小二乘法,在每个像素的局部邻域内,拟合这个二次多项式。 这就得到了每个像素的 $A$、$b$ 和 $c$。假设在时间 $t$ 和 $t + dt$ 的两个相邻帧中,同一个像素的亮度保持不变(亮度恒定假设)。 那么,对于时间 $t$ 的像素 $(x, y)$ 和时间 $t + dt$ 的像素 $(x + dx, y + dy)$,有: $$ I(x, y, t) = I(x + dx, y + dy, t + dt) $$
将这个假设应用到多项式展开中,并进行一系列数学推导(涉及泰勒展开和线性化),可以得到一个线性方程组,用于求解像素的运动矢量 $(dx, dy)$。 这个线性方程组可以表示为: $$ [A_1 + A_2] * d = -0.5 * (b_1 - b_2) $$ 其中:
$A_1$ 和 $b_1$ 是时间 $t$ 的帧中像素 $(x, y)$ 的多项式系数。
$A_2$ 和 $b_2$ 是时间 $t + dt$ 的帧中像素 $(x, y)$ 的多项式系数。
$d = [dx, dy]^T$ 是运动矢量。
通过求解这个线性方程组,可以得到每个像素的运动矢量$(dx, dy)$,即光流。
实践
import cv2
import numpy as np
def visualize_farneback_optical_flow_to_mp4(video_path, output_mp4_path):
"""
使用 Farneback 光流算法预览视频的光流场,并将结果保存为 MP4 视频文件。
Args:
video_path (str): 视频文件的路径。
output_mp4_path (str): 输出 MP4 文件的路径。
"""
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"无法打开视频文件: {video_path}")
return
ret, frame = cap.read()
if not ret:
print("无法读取视频的第一帧。")
return
height, width = frame.shape[:2]
fps = cap.get(cv2.CAP_PROP_FPS)
# 定义 VideoWriter 对象
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 或使用 'XVID'
out = cv2.VideoWriter(output_mp4_path, fourcc, fps, (width, height))
prvs = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
hsv = np.zeros_like(frame)
hsv[..., 1] = 255
while True:
ret, frame = cap.read()
if not ret:
break
next = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
flow = cv2.calcOpticalFlowFarneback(prvs, next, None, 0.5, 3, 15, 3, 5, 1.2, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
hsv[..., 0] = ang * 180 / np.pi / 2
hsv[..., 2] = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX)
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
out.write(bgr) # 写入帧到视频文件
cv2.imshow('Farneback 光流', bgr)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
elif k == ord('s'):
cv2.imwrite('opticalfb.png', frame)
cv2.imwrite('opticalhsv.png', bgr)
prvs = next
cap.release()
out.release()
cv2.destroyAllWindows()
print(f"光流 MP4 已保存到: {output_mp4_path}")
if __name__ == "__main__":
video_path = "Src/PyTest/ImageProcess/videos/3.mp4" # 替换为你的视频文件路径
output_mp4_path = "Src/PyTest/ImageProcess/videos/farneback_optical_flow.mp4" # 替换为你想保存 MP4 的路径
visualize_farneback_optical_flow_to_mp4(video_path, output_mp4_path)
2.1.3 Horn光流法
Horn-Schunck 算法是一种全局光流估计方法,它试图在整个图像范围内最小化一个能量函数,以获得平滑且符合亮度恒定假设的光流场。 与局部方法(如 Lucas-Kanade)不同,Horn-Schunck 算法考虑了整个图像的全局信息,因此对噪声和光照变化具有更强的鲁棒性。 Horn算法假设整个图像的光流都是平滑的。因此,它会尽量减少光流的扭曲,并优先选择那些更平滑的解。该流被表述为一个全局能量函数,然后寻求最小化。对于二维图像流,该函数如下: $$ {\displaystyle E=\iint \left[(I_{x}u+I_{y}v+I_{t})^{2}+\alpha ^{2}(\lVert \nabla u\rVert ^{2}+\lVert \nabla v\rVert ^{2})\right]{{\rm {d}}x{\rm {d}}y}} $$
$I_x$和$I_y$是图像的梯度。
$I_t$是时间导数。
$u$和$v$是光流场的分量。
$\alpha$是平滑项的权重。
该函数可以通过求解相关的多维欧拉-拉格朗日方程来最小化。这些方程是: $$ \begin{aligned} {\displaystyle {\frac {\partial E}{\partial u}}-{\frac {\partial }{\partial x}}{\frac {\partial E}{\partial u_{x}}}-{\frac {\partial }{\partial y}}{\frac {\partial E}{\partial u_{y}}}=0} \ {\displaystyle {\frac {\partial E}{\partial v}}-{\frac {\partial }{\partial x}}{\frac {\partial E}{\partial v_{x}}}-{\frac {\partial }{\partial y}}{\frac {\partial E}{\partial v_{y}}}=0} \end{aligned} $$
${\displaystyle L}$是能量表达式的被积函数,得出 $$ \begin{aligned} {\displaystyle I_{x}(I_{x}u+I_{y}v+I_{t})-\alpha ^{2}\Delta u=0}\ {\displaystyle I_{y}(I_{x}u+I_{y}v+I_{t})-\alpha ^{2}\Delta v=0} \end{aligned} $$
在实践中,拉普拉斯算子可以用有限差分进行数值近似,可以写成${\displaystyle \Delta u(x,y)=({\overline {u}}(x,y)-u(x,y))}$,${\displaystyle {\overline {u}}(x,y)}$是加权平均值${\displaystyle u}$在$位置 $(x,y)$ 处像素周围的邻域内计算。使用这个符号,上述方程组可以写成
$$ \begin{aligned} {\displaystyle (I_{x}^{2}+\alpha ^{2})u+I_{x}I_{y}v=\alpha ^{2}{\overline {u}}-I_{x}I_{t}}\ {\displaystyle I_{x}I_{y}u+(I_{y}^{2}+\alpha ^{2})v=\alpha ^{2}{\overline {v}}-I_{y}I_{t}} \end{aligned} $$
这是线性的${\displaystyle u}$和${\displaystyle v}$并且可以针对图像中的每个像素进行求解。然而,由于解依赖于流场的相邻值,因此在更新相邻值后必须重复求解。以下迭代方案是利用克莱姆规则推导出来的: $$ \begin{aligned} {\displaystyle u^{k+1}={\overline {u}}^{k}-{\frac {I_{x}(I_{x}{\overline {u}}^{k}+I_{y}{\overline {v}}^{k}+I_{t})}{\alpha ^{2}+I_{x}^{2}+I_{y}^{2}}}}\ {\displaystyle v^{k+1}={\overline {v}}^{k}-{\frac {I_{y}(I_{x}{\overline {u}}^{k}+I_{y}{\overline {v}}^{k}+I_{t})}{\alpha ^{2}+I_{x}^{2}+I_{y}^{2}}}} \end{aligned} $$ ${\displaystyle {\overline {u}}^{k}}$和${\displaystyle {\overline {v}}^{k}}$是${\displaystyle u}$和${\displaystyle v}$的平均值。
实践
import cv2
import numpy as np
from scipy.ndimage.filters import convolve as filter2
import os
from argparse import ArgumentParser
"""
see readme for running instructions
"""
def show_image(name, image):
if image is None:
return
cv2.imshow(name, image)
cv2.waitKey(0)
cv2.destroyAllWindows()
#compute magnitude in each 8 pixels. return magnitude average
def get_magnitude(u, v):
scale = 3
sum = 0.0
counter = 0.0
for i in range(0, u.shape[0], 8):
for j in range(0, u.shape[1],8):
counter += 1
dy = v[i,j] * scale
dx = u[i,j] * scale
magnitude = (dx**2 + dy**2)**0.5
sum += magnitude
mag_avg = sum / counter
return mag_avg
def visualize_optical_flow(u, v, img):
h, w = img.shape[:2]
hsv = np.zeros((h, w, 3), dtype=np.uint8)
magnitude, angle = cv2.cartToPolar(u, v)
hsv[..., 0] = angle * 180 / np.pi / 2
hsv[..., 1] = 255
hsv[..., 2] = cv2.normalize(magnitude, None, 0, 255, cv2.NORM_MINMAX)
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
return bgr
#compute derivatives of the image intensity values along the x, y, time
def get_derivatives(img1, img2):
#derivative masks
x_kernel = np.array([[-1, 1], [-1, 1]]) * 0.25
y_kernel = np.array([[-1, -1], [1, 1]]) * 0.25
t_kernel = np.ones((2, 2)) * 0.25
fx = filter2(img1,x_kernel) + filter2(img2,x_kernel)
fy = filter2(img1, y_kernel) + filter2(img2, y_kernel)
ft = filter2(img1, -t_kernel) + filter2(img2, t_kernel)
return [fx,fy, ft]
#input: images name, smoothing parameter, tolerance
#output: images variations (flow vectors u, v)
#calculates u,v vectors and draw quiver
def computeHS(beforeImg, afterImg, alpha, delta):
beforeImg = beforeImg.astype(float)
afterImg = afterImg.astype(float)
#removing noise
beforeImg = cv2.GaussianBlur(beforeImg, (5, 5), 0)
afterImg = cv2.GaussianBlur(afterImg, (5, 5), 0)
# set up initial values
u = np.zeros((beforeImg.shape[0], beforeImg.shape[1]))
v = np.zeros((beforeImg.shape[0], beforeImg.shape[1]))
fx, fy, ft = get_derivatives(beforeImg, afterImg)
avg_kernel = np.array([[1 / 12, 1 / 6, 1 / 12],
[1 / 6, 0, 1 / 6],
[1 / 12, 1 / 6, 1 / 12]], float)
iter_counter = 0
while True:
iter_counter += 1
u_avg = filter2(u, avg_kernel)
v_avg = filter2(v, avg_kernel)
p = fx * u_avg + fy * v_avg + ft
d = 4 * alpha**2 + fx**2 + fy**2
prev = u
u = u_avg - fx * (p / d)
v = v_avg - fy * (p / d)
diff = np.linalg.norm(u - prev, 2)
#converges check (at most 300 iterations)
if diff < delta or iter_counter > 300:
# print("iteration number: ", iter_counter)
break
return [u, v]
if __name__ == '__main__':
# Input and output video paths
input_video_path = "Src/PyTest/ImageProcess/videos/3.mp4" # 替换为你的视频文件路径
output_video_path = "Src/PyTest/ImageProcess/videos/horn_schunck.mp4" # 替换为你想保存 MP4 的路径
# Read the input video
cap = cv2.VideoCapture(input_video_path)
if not cap.isOpened():
print(f"Error opening video stream or file: {input_video_path}")
exit()
# Get video properties
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
frame_rate = cap.get(cv2.CAP_PROP_FPS)
# Define the codec and create VideoWriter object
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_video_path, fourcc, frame_rate, (frame_width, frame_height))
# Read the first frame
ret, frame1 = cap.read()
if not ret:
print("Failed to read the first frame!")
exit()
prev_gray = cv2.cvtColor(frame1, cv2.COLOR_BGR2GRAY)
# Process the video frame by frame
while(True):
ret, frame2 = cap.read()
if not ret:
break
# Convert to grayscale
gray = cv2.cvtColor(frame2, cv2.COLOR_BGR2GRAY)
# Compute Horn-Schunck optical flow
alpha = 15
delta = 10**-1
u, v = computeHS(prev_gray, gray, alpha, delta)
# Visualize the optical flow
flow_vis = visualize_optical_flow(u, v, prev_gray)
# Write the frame to the output video
out.write(flow_vis)
# Display the resulting frame
#cv2.imshow('Horn-Schunck Optical Flow', flow_vis)
#if cv2.waitKey(1) & 0xFF == ord('q'):
# break
# Update the previous frame
prev_gray = gray
# Release video capture and writer objects
cap.release()
out.release()
# Destroy all the windows
cv2.destroyAllWindows()
print(f"Video saved to {output_video_path}")

3 深度学习算法
深度学习相关的光流算法有很多,这里只简单介绍FlowNet。
3.1 FlowNet
FlowNet 是一个开创性的工作,它首次展示了使用卷积神经网络 (CNN) 直接学习光流估计的可行性。 在此之前,光流估计主要依赖于传统的优化方法,这些方法计算量大,速度慢。 FlowNet 的出现为光流估计领域带来了新的思路,并为后续的深度学习光流算法奠定了基础。

FlowNet 的核心思想是利用 CNN 强大的特征提取和学习能力,直接从图像数据中学习光流的模式。 通过大量的训练数据,CNN 可以学习到图像特征与光流之间的映射关系,从而实现快速且相对准确的光流估计。FlowNet 包含两个主要的变体:FlowNetS (Simple) 和 FlowNetC (Correlation)。
FlowNetS (Simple):
输入: 将两张连续的图像 (I1, I2) 简单地堆叠在一起,形成一个 6 通道的输入。
网络结构: 一个标准的 CNN 结构,包含卷积层、池化层和全连接层。
输出: 光流场 (u, v),其中 u 和 v 分别表示水平和垂直方向上的运动矢量。
特点: 结构简单,易于实现,但精度相对较低。
FlowNetC (Correlation):
输入: 两张连续的图像 (I1, I2) 分别经过一个 CNN 提取特征。
相关层 (Correlation Layer): 将两组特征进行相关性计算,得到一个相关性图 (correlation map)。 相关性图表示了 I1 中每个像素与 I2 中所有像素之间的相似度。
网络结构: 将相关性图与 I1 的特征图连接在一起,输入到一个 CNN 中。
输出: 光流场 (u, v)。
特点: 通过相关性计算,可以更好地匹配对应点,从而提高精度。

FlowNet 使用监督学习的方式进行训练,目标是最小化预测的光流场与真实光流场之间的误差。 常用的损失函数包括 L1 损失、L2 损失以及 EPE (End-Point Error)。EPE 是光流估计中最常用的评估指标之一,它衡量的是预测光流矢量与真实光流矢量之间的欧氏距离。 对于每个像素 (x, y),EPE 定义为: $$ EPE(x, y) = || (u_{pred}(x, y), v_{pred}(x, y)) - (u_{gt}(x, y), v_{gt}(x, y)) ||2 $$ 其中,$u{pred}(x, y)$ 和 $v_{pred}(x, y)$ 是预测的光流场,$u_{gt}(x, y)$ 和 $v_{gt}(x, y)$ 是真实的光流场。
L1 损失是 EPE 的一种变体,它使用 L1 范数来衡量光流矢量之间的差异: $$ L1(x, y) = || (u_{pred}(x, y), v_{pred}(x, y)) - (u_{gt}(x, y), v_{gt}(x, y)) ||1 $$ L2 损失是 EPE 的另一种变体,它使用 L2 范数来衡量光流矢量之间的差异: $$ L2(x, y) = || (u{pred}(x, y), v_{pred}(x, y)) - (u_{gt}(x, y), v_{gt}(x, y)) ||_2 $$

FlowNet的优缺点:
优点:
速度快: 相对于传统的优化方法,FlowNet 的速度非常快,可以实现实时的光流估计。
端到端学习: FlowNet 可以直接从图像数据中学习光流,无需手动设计特征。
开创性: FlowNet 开创了深度学习光流估计的先河,为后续的研究奠定了基础。
缺点:
精度较低: 相对于传统的优化方法,FlowNet 的精度较低。
依赖于训练数据: FlowNet 的性能 сильно зависит от качества и количества обучающих данных。
泛化能力有限: FlowNet 在训练数据之外的场景中表现可能不佳。
4 总结
算法 |
原理 |
优点 |
缺点 |
适用场景 |
|---|---|---|---|---|
LK |
局部恒定性,小运动假设 |
计算简单,速度快,易于实现 |
对噪声敏感,对大位移估计差,容易受光照变化影响,依赖梯度信息 |
小运动场景,光照变化不大的场景,需要快速计算的场景 |
Farnebäck |
多项式展开 |
对噪声具有一定的鲁棒性,可以处理一定程度的大位移 |
计算复杂度较高,对参数比较敏感 |
运动幅度较大的场景,需要较高精度的场景 |
Horn-Schunck |
全局平滑性约束 |
可以生成平滑的光流场,对噪声具有一定的鲁棒性 |
计算复杂度高,速度慢,容易过度平滑,对光照变化敏感 |
需要平滑光流场的场景,对精度要求较高的场景 |
深度学习算法 |
CNN 学习图像特征与光流之间的映射关系 |
速度快,精度高,可以处理复杂的场景 (遮挡、光照变化、运动模糊) |
需要大量的训练数据,对训练数据的质量要求高,泛化能力可能有限,计算资源消耗较大 |
需要高精度和高速度的场景,复杂的场景,例如自动驾驶、机器人和视频分析 |