STL源码分析(基于LLVM实现)
1 allocator
1.1 allocator
1.1.1 简介
allocator是STL中对一个堆内存分配器,是对内存申请工作的一个封装,将内存的申请和成员的构造抽象开来方便控制。基本上,C++标准库中的容器的默认分配器都是allocator。在C++中分配器是通过模板参数的方式指定给对应的容器,默认就是allocator,用户自己也可以实现自己的内存管理类,对堆的内存进行有效的管理也可以将对应的分配器指定给容器使用(前提是接口保持一致)。
std::allocator<int> alloc1;
// demonstrating the few directly usable members
static_assert(std::is_same_v<int, decltype(alloc1)::value_type>);
int* p1 = alloc1.allocate(1); // space for one int
alloc1.deallocate(p1, 1); // and it is gone
1.1.2 allocator的实现
先简单看下allocator的声明,其中_LIBCPP_TEMPLATE_VIS是不同版本编译期的可见性宏,标准库的源码中有大量类似的宏,我们大概直到意思即可不用深究。
template <class _Tp>
class _LIBCPP_TEMPLATE_VIS allocator
: private __non_trivial_if<!is_void<_Tp>::value, allocator<_Tp> >
allocator继承的__non_trivial_if是一个空类,该类利用cpp的CRTP实现编译期的多态。该类由一个偏特化版本区别是带有non-trivial的构造函数。在allocator中非void类型都是匹配第二个,void类型匹配第一个。而模板的第二个参数_Unique是为了保持菱形继承过程中的ABI稳定而设置的。
template <bool _Cond, class _Unique>
struct __non_trivial_if { };
template <class _Unique>
struct __non_trivial_if<true, _Unique> {
_LIBCPP_INLINE_VISIBILITY
_LIBCPP_CONSTEXPR __non_trivial_if() _NOEXCEPT { }
};
allocate函数
allocate函数是用来分配堆内存,可以看到内部实现调用了operator new。该函数实现的基本逻辑就是检查当前希望分配的大小是否可满足(allocator_traits下面会详细描述,暂时就理解为一个类型系统),不满足就会抛出异常,否则会调用对应的分配函数进行分配。__libcpp_is_constant_evaluated用来判断当前函数是否为constexpr。libcpp_alocate的区别内部依然调用了::operator new实现,只是有内存对齐。另外,这里不用new,而是使用::operator new应该是为了避免用户承载了new```的实现而导致无法真正分配到内存。
_VSTD类似于std,也是一个名字空间。_VSTDis now an alias forstdinstead ofstd::_LIBCPP_ABI_NAMESPACE. This is technically not a functional change, except for folks that might have been using_VSTDin creative ways (which has never been officially supported). ————来源libcxx/docs/ReleaseNotes.rs
_LIBCPP_NODISCARD_AFTER_CXX17 _LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX20
_Tp* allocate(size_t __n) {
if (__n > allocator_traits<allocator>::max_size(*this))
__throw_bad_array_new_length();
if (__libcpp_is_constant_evaluated()) {
return static_cast<_Tp*>(::operator new(__n * sizeof(_Tp)));
} else {
return static_cast<_Tp*>(_VSTD::__libcpp_allocate(__n * sizeof(_Tp), _LIBCPP_ALIGNOF(_Tp)));
}
}
deallocate
deallocate是用来释放内存的,其实现和allocate基本类似。
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX20
void deallocate(_Tp* __p, size_t __n) _NOEXCEPT {
if (__libcpp_is_constant_evaluated()) {
::operator delete(__p);
} else {
_VSTD::__libcpp_deallocate((void*)__p, __n * sizeof(_Tp), _LIBCPP_ALIGNOF(_Tp));
}
}
construct和destroy
construct(仅仅在对应内存上构造对象)和destroy(仅仅调用析构函数)函数的实现比较简单就是直接显式调用构造函数和析构函数。
template <class _Up, class... _Args>
_LIBCPP_DEPRECATED_IN_CXX17 _LIBCPP_INLINE_VISIBILITY
void construct(_Up* __p, _Args&&... __args) {
::new ((void*)__p) _Up(_VSTD::forward<_Args>(__args)...);
}
_LIBCPP_DEPRECATED_IN_CXX17 _LIBCPP_INLINE_VISIBILITY
void destroy(pointer __p) {
__p->~_Tp();
}
rebind
获取另一个类型的allocator,对于带有节点的数据结构,当前allocator只能管理节点数据的内存但是对于节点本身是无法管理的,使用这样的方式能够让二者的管理统一。
template <class _Up>
struct _LIBCPP_DEPRECATED_IN_CXX17 rebind {
typedef allocator<_Up> other;
};
1.2 allocator特化版本
1.2.1 const allocator
const特化版本主要是allocate时返回的是const的函数指针,且在释放时会通过const_cast去除const进行释放。
const _Tp* allocate(size_t __n) {
if (__n > allocator_traits<allocator>::max_size(*this))
__throw_bad_array_new_length();
if (__libcpp_is_constant_evaluated()) {
return static_cast<const _Tp*>(::operator new(__n * sizeof(_Tp)));
} else {
return static_cast<const _Tp*>(_VSTD::__libcpp_allocate(__n * sizeof(_Tp), _LIBCPP_ALIGNOF(_Tp)));
}
}
void deallocate(const _Tp* __p, size_t __n) {
if (__libcpp_is_constant_evaluated()) {
::operator delete(const_cast<_Tp*>(__p));
} else {
_VSTD::__libcpp_deallocate((void*) const_cast<_Tp *>(__p), __n * sizeof(_Tp), _LIBCPP_ALIGNOF(_Tp));
}
}
1.2.2 void allocator
allocator的void特化版本就是一个空壳子,什么也没有。
template <>
class _LIBCPP_TEMPLATE_VIS allocator<void>
{
#if _LIBCPP_STD_VER <= 17 || defined(_LIBCPP_ENABLE_CXX20_REMOVED_ALLOCATOR_MEMBERS)
public:
_LIBCPP_DEPRECATED_IN_CXX17 typedef void* pointer;
_LIBCPP_DEPRECATED_IN_CXX17 typedef const void* const_pointer;
_LIBCPP_DEPRECATED_IN_CXX17 typedef void value_type;
template <class _Up> struct _LIBCPP_DEPRECATED_IN_CXX17 rebind {typedef allocator<_Up> other;};
#endif
};
1.3 类型萃取allocator_traits
allocator_traits将当前类型的类型抽象到一个类中,其实现就是一个类型集合。allocator_traits额外提供了一些关于内存分配的函数,比如max_size等。
template <class _Alloc>
struct _LIBCPP_TEMPLATE_VIS allocator_traits
{
using allocator_type = _Alloc;
using value_type = typename allocator_type::value_type;
using pointer = typename __pointer<value_type, allocator_type>::type;
using const_pointer = typename __const_pointer<value_type, pointer, allocator_type>::type;
using void_pointer = typename __void_pointer<pointer, allocator_type>::type;
using const_void_pointer = typename __const_void_pointer<pointer, allocator_type>::type;
using difference_type = typename __alloc_traits_difference_type<allocator_type, pointer>::type;
using size_type = typename __size_type<allocator_type, difference_type>::type;
using propagate_on_container_copy_assignment = typename __propagate_on_container_copy_assignment<allocator_type>::type;
using propagate_on_container_move_assignment = typename __propagate_on_container_move_assignment<allocator_type>::type;
using propagate_on_container_swap = typename __propagate_on_container_swap<allocator_type>::type;
using is_always_equal = typename __is_always_equal<allocator_type>::type;
};
template <class _Ap = _Alloc, class = void, class =
__enable_if_t<!__has_max_size<const _Ap>::value> >
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX20
static size_type max_size(const allocator_type&) _NOEXCEPT {
return numeric_limits<size_type>::max() / sizeof(value_type);
}
2 string和string_view
std::string的实现实际上就是basic_string,我们经常使用的就是两种typedef basic_string<char> string;和typedef basic_string<wchar_t>wstring。std::string使用的分配器是allocator<char>,就是简单的new char,而trait使用的是char_traits。
template <class _CharT, class _Traits = char_traits<_CharT>, class _Allocator = allocator<_CharT> >
class _LIBCPP_TEMPLATE_VIS basic_string;
using string = basic_string<char>;
2.1 char_traits
char_traits就是char类型的萃取器,抽象了和当前类型相关的类型集,以及类型相关的一些操作。
struct _LIBCPP_DEPRECATED_("char_traits<T> for T not equal to char, wchar_t, char8_t, char16_t or char32_t is non-standard and is provided for a temporary period. It will be removed in LLVM 18, so please migrate off of it.")
char_traits
{
using char_type = _CharT;
using int_type = int;
using off_type = streamoff;
using pos_type = streampos;
using state_type = mbstate_t;
};
下面这些实现实际上是通用的char_traits的实现,因为使用的for-loop性能上完全依赖于编译器优化,如果编译器无法判断两块内存是否overlap的话,对于trival type性能可能不如memcpy等整块内存拷贝或者move的API。从源码的注释我们也能看到这个类是不建议使用的,应该使用对应的特化版本,特化版本比如char_traits<char>使用了std::copy等API可以对操作进行加速。
char_traits<T> for T not equal to char, wchar_t, char8_t, char16_t or char32_t is non-standard and is provided for a temporary period. It will be removed in LLVM 18, so please migrate off of it
assign lt eq
这三个函数就是对operator =,operator == ,operator <的封装。
static inline void _LIBCPP_CONSTEXPR_SINCE_CXX17
assign(char_type& __c1, const char_type& __c2) _NOEXCEPT {__c1 = __c2;}
static inline _LIBCPP_CONSTEXPR bool eq(char_type __c1, char_type __c2) _NOEXCEPT
{return __c1 == __c2;}
static inline _LIBCPP_CONSTEXPR bool lt(char_type __c1, char_type __c2) _NOEXCEPT
{return __c1 < __c2;}
compare
遍历当前字符串,逐个字符比较,需要保证输入的字符串长度至少为n负责会越界。
static _LIBCPP_CONSTEXPR_SINCE_CXX17 int compare(const char_type* __s1, const char_type* __s2, size_t __n) {
for (; __n; --__n, ++__s1, ++__s2){
if (lt(*__s1, *__s2))
return -1;
if (lt(*__s2, *__s1))
return 1;
}
return 0;
}
length
获取字符串的长度,遍历字符串,以char_type(0)为结束点,实现和strlen相同。
_LIBCPP_INLINE_VISIBILITY static _LIBCPP_CONSTEXPR_SINCE_CXX17 size_t length(const char_type* __s) {
size_t __len = 0;
for (; !eq(*__s, char_type(0)); ++__s)
++__len;
return __len;
}
find 从头到尾遍历字符串,直到找到对应的值为止。
_LIBCPP_INLINE_VISIBILITY static _LIBCPP_CONSTEXPR_SINCE_CXX17
const char_type* find(const char_type* __s, size_t __n, const char_type& __a) {
for (; __n; --__n){
if (eq(*__s, __a))
return __s;
++__s;
}
return nullptr;
}
move: 字符串移动。可以看到针对当前输入的两块内存的地址相对位置选择了不同方向的拷贝动作,这样做是为了正确处理存在内存交叉的两块内存的字符串。
static char_type* move(char_type* __s1, const char_type* __s2, size_t __n) {
if (__n == 0) return __s1;
char_type* __r = __s1;
if (__s1 < __s2){
for (; __n; --__n, ++__s1, ++__s2)
assign(*__s1, *__s2);
}
else if (__s2 < __s1){
__s1 += __n;
__s2 += __n;
for (; __n; --__n)
assign(*--__s1, *--__s2);
}
return __r;
}
copy
字符串拷贝,这里的动作基本上和move相同但是并没有进行地址交错的处理。因为move的语义是移动,旧的丢弃,而copy的语义是拷贝,旧的应该保留。
_LIBCPP_INLINE_VISIBILITY static _LIBCPP_CONSTEXPR_SINCE_CXX20 char_type* copy(char_type* __s1, const char_type* __s2, size_t __n) {
if (!__libcpp_is_constant_evaluated()) {
_LIBCPP_ASSERT(__s2 < __s1 || __s2 >= __s1+__n, "char_traits::copy overlapped range");
}
char_type* __r = __s1;
for (; __n; --__n, ++__s1, ++__s2)
assign(*__s1, *__s2);
return __r;
}
2.2 string
2.2.1 内存布局
std::string中内存布局根据_LIBCPP_ABI_ALTERNATE_STRING_LAYOUT有所不同,就是下面列的这种,__data__域在类开头,这样在某些需要对齐的场景比较有优势。另一种是将__data___等四个成员完全反向陈列。
struct __long{
struct _LIBCPP_PACKED {
size_type __is_long_ : 1;
size_type __cap_ : sizeof(size_type) * CHAR_BIT - 1;
};
size_type __size_;
pointer __data_;
};
enum {__min_cap = (sizeof(__long) - 1)/sizeof(value_type) > 2 ? (sizeof(__long) - 1)/sizeof(value_type) : 2};
struct __short{
struct _LIBCPP_PACKED {
unsigned char __is_long_ : 1;
unsigned char __size_ : 7;
};
char __padding_[sizeof(value_type) - 1];
value_type __data_[__min_cap];
};
struct __raw{
size_type __words[__n_words];
};
struct __rep{
union
{
__long __l;
__short __s;
__raw __r;
};
};
__compressed_pair<__rep, allocator_type> __r_;
从上面的定义中可以看出,string针对不同场景的优化,对于小字符串(一般为15或23)直接存储在栈上即SSO优化,而对于大字符串会通过堆来存储。__compressed_pair是一种可以利用编译期一些优化的组合类,可以理解为pair。
__compressed_pair
__compressed_pair其实就是两个变量的集合,类似pair,只不过针对不同的场景进行了优化。将标准库中的代码简化之后主要的代码就是下面这段。对于可继承的类型,直接会通过继承的方式构造,这样可以对于空基类可以触发EBO(https://en.cppreference.com/w/cpp/language/ebo),节省一部分内存;而对于不可继承的类型直接就创建一个成员。
template <class _Tp, int _Idx, bool _CanBeEmptyBase = is_empty<_Tp>::value && !__libcpp_is_final<_Tp>::value>
struct __compressed_pair_elem {
private:
_Tp __value_;
};
template <class _Tp, int _Idx>
struct __compressed_pair_elem<_Tp, _Idx, true> : private _Tp {};
template <class _T1, class _T2>
class __compressed_pair : private __compressed_pair_elem<_T1, 0>, private __compressed_pair_elem<_T2, 1> {};
2.2.2 string的构造与析构
构造
string的第一种构造默认初始化,调用__default_init创建一个空的__rep,没有进行其他操作。第二种就是调用__init创建内存。
首先检查当前输出参数的长度是否符合SSO优化的前提,满足的话直接使用short版本,不满足的话再通过allocator分配内存。最后通过char_traits::copy将字符拷贝到内存上。
template <class _CharT, class _Traits, class _Allocator>
_LIBCPP_CONSTEXPR_SINCE_CXX20 void basic_string<_CharT, _Traits, _Allocator>::__init(const value_type* __s, size_type __sz, size_type __reserve){
if (__libcpp_is_constant_evaluated())
__r_.first() = __rep();
if (__reserve > max_size()) //长度过长
__throw_length_error();
pointer __p;
if (__fits_in_sso(__reserve)){//是否满足sso优化的条件
__set_short_size(__sz);
__p = __get_short_pointer();
}
else{
auto __allocation = std::__allocate_at_least(__alloc(), __recommend(__reserve) + 1);
__p = __allocation.ptr;
__begin_lifetime(__p, __allocation.count);
__set_long_pointer(__p); //设置long.__data__
__set_long_cap(__allocation.count);//设置long.__cap__
__set_long_size(__sz); //设置long.__sz__
}
traits_type::copy(std::__to_address(__p), __s, __sz);//拷贝内存,逐个拷贝
traits_type::assign(__p[__sz], value_type());//末尾插入\0
}
能够注意到申请内存时,实际申请的大小是__recommend(__reserve) + 1,起始就是字节对齐的长度。
size_type __recommend(size_type __s) _NOEXCEPT{
if (__s < __min_cap) {
if (__libcpp_is_constant_evaluated())
return static_cast<size_type>(__min_cap);
else
return static_cast<size_type>(__min_cap) - 1;
}
//__alignment == 16
size_type __guess = __align_it<sizeof(value_type) < __alignment ?
__alignment/sizeof(value_type) : 1 > (__s+1) - 1;
if (__guess == __min_cap) ++__guess;
return __guess;
}
另外移动拷贝构造就是直接接管原字符的内存,并在原字符内存上构建一个空字符串。之后输入的字符串的allocator和当前字符串不同时才会逐个拷贝,也就是说move后的源字符串是会失效的,这也符合move的语义。而对于const _CharT* __s输入的构造函数和拷贝构造函数直接就是调用的__init申请拷贝内存。
_LIBCPP_HIDE_FROM_ABI _LIBCPP_CONSTEXPR_SINCE_CXX20
basic_string(basic_string&& __str, const allocator_type& __a) : __r_(__default_init_tag(), __a) {
if (__str.__is_long() && __a != __str.__alloc()) // copy, not move
__init(std::__to_address(__str.__get_long_pointer()), __str.__get_long_size());
else {
if (__libcpp_is_constant_evaluated())
__r_.first() = __rep();
__r_.first() = __str.__r_.first();
__str.__default_init();
}
std::__debug_db_insert_c(this);
if (__is_long())
std::__debug_db_swap(this, &__str);
}
析构
析构就比较简单了,如果是长字符,就会调用deallocate释放内存。
basic_string<_CharT, _Traits, _Allocator>::~basic_string(){
std::__debug_db_erase_c(this);
if (__is_long())
__alloc_traits::deallocate(__alloc(), __get_long_pointer(), __get_long_cap());
}
2.2.3 string的一些操作函数
扩容
string的扩容是通过__grow_by_and_replace进行的,另一个实现__grow_by也是一样的逻辑,基本的流程是:
检查大小是否超出最大值;
计算期望得到的cap大小,值为
std::max(2 * old_cap, new_size);通过
allocator分配一块儿新内存;将旧内存中的值拷贝到新内存中;
如果旧内存为堆分配的则释放内存;
设置一些参数,结尾插入空字符。
void
basic_string<_CharT, _Traits, _Allocator>::__grow_by_and_replace
(size_type __old_cap, size_type __delta_cap, size_type __old_sz,
size_type __n_copy, size_type __n_del, size_type __n_add, const value_type* __p_new_stuff){
size_type __ms = max_size();
if (__delta_cap > __ms - __old_cap - 1)
__throw_length_error();
pointer __old_p = __get_pointer();
size_type __cap = __old_cap < __ms / 2 - __alignment ?
__recommend(std::max(__old_cap + __delta_cap, 2 * __old_cap)) :
__ms - 1;
auto __allocation = std::__allocate_at_least(__alloc(), __cap + 1);
pointer __p = __allocation.ptr;
__begin_lifetime(__p, __allocation.count);
std::__debug_db_invalidate_all(this);
if (__n_copy != 0)
traits_type::copy(std::__to_address(__p),
std::__to_address(__old_p), __n_copy);
if (__n_add != 0)
traits_type::copy(std::__to_address(__p) + __n_copy, __p_new_stuff, __n_add);
size_type __sec_cp_sz = __old_sz - __n_del - __n_copy;
if (__sec_cp_sz != 0)
traits_type::copy(std::__to_address(__p) + __n_copy + __n_add,
std::__to_address(__old_p) + __n_copy + __n_del, __sec_cp_sz);
if (__old_cap+1 != __min_cap || __libcpp_is_constant_evaluated())
__alloc_traits::deallocate(__alloc(), __old_p, __old_cap+1);
__set_long_pointer(__p);
__set_long_cap(__allocation.count);
__old_sz = __n_copy + __n_add + __sec_cp_sz;
__set_long_size(__old_sz);
traits_type::assign(__p[__old_sz], value_type());
}
缩容
string缩容有两种:一种是调用__null_terminate_at插入空字符,实际的大小并未发生变化;另一种是调用__shrink_or_extend(实际实现就是申请新内存拷贝旧的,释放旧的),__cap__会变化但是__sz不会变化。
basic_string& __null_terminate_at(value_type* __p, size_type __newsz) {
__set_size(__newsz);
__invalidate_iterators_past(__newsz);
traits_type::assign(__p[__newsz], value_type());
return *this;
}
其他的实现就是在assign,move,copy以及以上函数的基础上操作,就不再罗列。算法相关的函数等看算法的时候再说。
2.3 string_view
string_view用来持有字符串,也就是说他只是一个wrapper,并不对持有的字符串负责,也就没有拷贝析构等操作,相比于string性能上要好不少。
template<class _CharT, class _Traits = char_traits<_CharT> >
class _LIBCPP_TEMPLATE_VIS basic_string_view;
typedef basic_string_view<char> string_view;
string_view的结构非常简单,就是一个指针和长度,在进行构造时也仅仅是浅拷贝,将对应的指针传递给成员。也就是说在使用string_view时要对齐管理的内存及其小心,避免在内存已经失效时还用string_view访问。
It is the programmer's responsibility to ensure that std::string_view does not outlive the pointed-to character array
template<class _CharT, class _Traits>
class basic_string_view {
private:
const value_type* __data_;
size_type __size_;
};
basic_string_view(const _CharT* __s, size_type __len) _NOEXCEPT
: __data_(__s), __size_(__len){}
3 vector
vector是标准库中的连续存储的容器,也就是容器中说任意两个索引上相邻的元素的地址也是相邻的,可以通过索引随机访问。vector中的元素默认是通过堆内存管理的,在进行空间分配时一般会比时机需求的空间要大,即capacity_size,这样能够避免在插入元素时频繁申请内存导致的性能问题(如果频繁申请内存导致页置换的话还是很耗时的)。
先看下容器的定义,和其他容器一样都是一个模板类。_Tp就是类型,而_Allocator是进行内存管理的分配器,默认分配器就是通过::operator new和::operator delete申请和释放内存的。
template <class _Tp, class _Allocator /* = allocator<_Tp> */>
class _LIBCPP_TEMPLATE_VIS vector
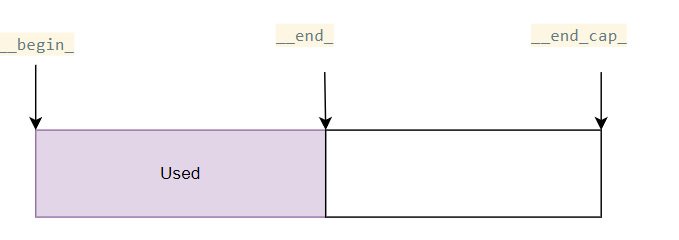
vector的内存布局比较简单如下图,有三个指针分别指向了对应的开始地址,已使用部分的尾地址,申请到的内存的尾地址,[__begin_, __end_)之间是已经使用的内存部分,[__end_, __end_cap_)是申请了但是未使用的部分(保留这一部分是为了避免插入元素时频繁allocate而可能出现的性能问题。)
private:
pointer __begin_ = nullptr;
pointer __end_ = nullptr;
__compressed_pair<pointer, allocator_type> __end_cap_ =
__compressed_pair<pointer, allocator_type>(nullptr, __default_init_tag());
构造和销毁
vector的构造比较简单,就是先通过allocator申请一块内存,然后通过for循环逐个构造对象。构造时通过for循环实现,由于没有利用CPU的一些SMID指令的优化,必然效率不是很好。
vector(size_type __n, const value_type& __x, const allocator_type& __a) : __end_cap_(nullptr, __a){
std::__debug_db_insert_c(this);
if (__n > 0){
__vallocate(__n);
__construct_at_end(__n, __x);
}
}
vector<_Tp, _Allocator>::__construct_at_end(size_type __n, const_reference __x){
_ConstructTransaction __tx(*this, __n);
const_pointer __new_end = __tx.__new_end_;
for (pointer __pos = __tx.__pos_; __pos != __new_end; __tx.__pos_ = ++__pos) {
__alloc_traits::construct(this->__alloc(), std::__to_address(__pos), __x);
}
}
销毁就比较直接,通过一个包装器__destroy_vector,先clear再调用deallocate释放内存。
__vec_.__clear();
__alloc_traits::deallocate(__vec_.__alloc(), __vec_.__begin_, __vec_.capacity());;
clear
clear函数只会针对析构容器中的每一个函数并不会释放当前容器中的内存。因此在进行容器释放时需要注意,如果期望释放内存的话可以通过vector().swap(vec)的方式或者在调用clear之后调用shrink_to_fit 调整内存大小。
void clear() _NOEXCEPT{
size_type __old_size = size();
__clear();
__annotate_shrink(__old_size); //看源码里面什么也不会做
std::__debug_db_invalidate_all(this);
}
void __clear() _NOEXCEPT {__base_destruct_at_end(this->__begin_);}
void __base_destruct_at_end(pointer __new_last) _NOEXCEPT {
pointer __soon_to_be_end = this->__end_;
while (__new_last != __soon_to_be_end) //依然是一个完整的循环析构
__alloc_traits::destroy(__alloc(), std::__to_address(--__soon_to_be_end));
this->__end_ = __new_last;
}
push_back
push_back时,如果当前有足够的的大小则会在尾部构建一个对象,扩容的大小是按照现有大小的2倍来,即std::min(max_size(), std::max(current_cap + 1, 2 * current_cap)),简单的理解就是在条件允许的情况下扩容2倍。
void vector<_Tp, _Allocator>::__push_back_slow_path(_Up&& __x){
allocator_type& __a = this->__alloc();
//__split_buffer就是一个包装器
__split_buffer<value_type, allocator_type&> __v(__recommend(size() + 1), size(), __a);
// __v.push_back(std::forward<_Up>(__x));
__alloc_traits::construct(__a, std::__to_address(__v.__end_), std::forward<_Up>(__x));
__v.__end_++;
__swap_out_circular_buffer(__v);//这个函数没有干什么就是将__v中的size设置给当前的vector
}
emplace_back
emplace_back和push_back基本相同都是向容器中插入元素,如果对于插入vector::value_type类型的对象二者是没有区别的,push_back也实现了右值的重载,不存在push_back对于右值会多次拷贝的情况。主要的区别是emplace_back通过可变参数模板将参数直接传递给了构建器也就意味着同样的代码emplace_back直接在对应的内存上构建对象,而相比之下push_back是先构建再拷贝。
void vector<_Tp, _Allocator>::emplace_back(_Args&&... __args)
resize
resize的实现比较直接,内存小了就扩容,大了就析构但是并不释放内存。
void vector<_Tp, _Allocator>::resize(size_type __sz, const_reference __x){
size_type __cs = size();
if (__cs < __sz)
this->__append(__sz - __cs, __x);
else if (__cs > __sz)
this->__destruct_at_end(this->__begin_ + __sz);//只会析构对象,不会释放内存
}
shrink_to_fit
vector<bool, _Allocator>::shrink_to_fit() _NOEXCEPT{
if (__external_cap_to_internal(size()) > __cap()){
vector(*this, allocator_type(__alloc())).swap(*this);
}
}
vector<bool>基本上被建议放弃使用了,所以就不深入了。
4 array
array的实现比较简单就是一个简单的栈数组的包装器。就不详细描述了。
template <class _Tp, size_t _Size>
struct _LIBCPP_TEMPLATE_VIS array
{
// types:
typedef array __self;
typedef _Tp value_type;
typedef value_type& reference;
typedef const value_type& const_reference;
typedef value_type* iterator;
typedef const value_type* const_iterator;
typedef value_type* pointer;
typedef const value_type* const_pointer;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef _VSTD::reverse_iterator<iterator> reverse_iterator;
typedef _VSTD::reverse_iterator<const_iterator> const_reverse_iterator;
_Tp __elems_[_Size];
};
5 iterator
迭代器是一种抽象设计模式,旨在不暴露实现细节的情况下按照某种特定的顺序访问类内的数据。简单的说,就类似数组和访问数组的指针的关系。这样就可以将实际承载数据的容器和处理容器的一些算法分离开,算法只需要通过迭代器访问类内的数据完成一些通用的算法处理。但是由于高度抽象没有足够的细节,算法处理只能根据有限的信息做通用处理没法针对特定的场景选择更加优秀的处理方式。一些容器比如string就实现了自己的一套算法处理API。
迭代器是用来访问容器中数据成员的抽象接口,它的行为类似于指针对象,可以读写对应索引的成员,并进行--,++等操作改变索引。
5.1 iterator
STL的迭代器就是规定了6大类型的迭代器以及迭代器对应的iterator_traits,每个迭代器的访问规则都是固定的,比如前向迭代器可以++,随机访问迭代器可以+n。具体的迭代器实现和具体的容器实现是强相关的,每个迭代器的实现就有具体的容器负责。当外部希望通过迭代器操作容器的元素时只需要根据规定的语义访问即可,如果期望了解嗲到期存放的类型等信息可以使用iterator_traits获取,这样就保证了内部的实现对外是完全隔离的。
5.2 iterator traits
STL中有6类迭代器:输入迭代器,输出迭代器,前向迭代器,双向迭代器,连续存储迭代器(C++20新增的),随机访问迭代器。
输入迭代器:索引对内的内存可读,比如
istream_iterator;输出迭代器:索引对应的内存可写,比如
ostream_iterator;前向迭代器:数据可读写,索引的方向只能向前,可以
++,但是不能向后不支持--;双向迭代器:在前向迭代器的基础上,支持
--;随机访问迭代器:功能完全和指针相同,可以通过随机指针随机访问容器内的元素,比如
iter+n访问相对当前位置后第n个元素。连序存储迭代器:通过该迭代器访问的元素都保证数据存储是连续的。
下面是libcxx中不同类型迭代器的标识,这些类虽然是空类,但是是不同的类型就可以通过模板推导的方式选择正确的迭代器。
struct _LIBCPP_TEMPLATE_VIS input_iterator_tag {};
struct _LIBCPP_TEMPLATE_VIS output_iterator_tag {};
struct _LIBCPP_TEMPLATE_VIS forward_iterator_tag : public input_iterator_tag {};
struct _LIBCPP_TEMPLATE_VIS bidirectional_iterator_tag : public forward_iterator_tag {};
struct _LIBCPP_TEMPLATE_VIS random_access_iterator_tag : public bidirectional_iterator_tag {};
#if _LIBCPP_STD_VER >= 20
struct _LIBCPP_TEMPLATE_VIS contiguous_iterator_tag : public random_access_iterator_tag {};
#endif
STL是迭代器类型的类型萃取器,可以根据当前迭代器的类型推断出一些容器迭代器中需要的类型。STL要求所有迭代器都应该提供这五个基本的类型以方便萃取器获取具体的类型,参考iterator_traits
template <class _Iter>
struct __iterator_traits_impl<_Iter, true>
{
typedef typename _Iter::difference_type difference_type;
typedef typename _Iter::value_type value_type;
typedef typename _Iter::pointer pointer;
typedef typename _Iter::reference reference;
typedef typename _Iter::iterator_category iterator_category;
};
//指针的特化版本
struct _LIBCPP_TEMPLATE_VIS iterator_traits<_Tp*>{
typedef ptrdiff_t difference_type;
typedef __remove_cv_t<_Tp> value_type;
typedef _Tp* pointer;
typedef _Tp& reference;
typedef random_access_iterator_tag iterator_category;
#if _LIBCPP_STD_VER >= 20
typedef contiguous_iterator_tag iterator_concept;
#endif
};
5.3 不同迭代器的实现
5.3.1 容器的迭代器
5.3.1.1 __wrap_iter
vector的迭代器时__wrap_iter<pointer>就是一个指针的包装器,将指针的一系列操作封装了一遍,也就是vector的迭代器就是一个指针没有什么特别之处。而array的迭代器直接就是一个value_type*类型,就是一个裸指针。
template <class _Iter>
class __wrap_iter
{
public:
typedef _Iter iterator_type;
typedef typename iterator_traits<iterator_type>::value_type value_type;
typedef typename iterator_traits<iterator_type>::difference_type difference_type;
typedef typename iterator_traits<iterator_type>::pointer pointer;
typedef typename iterator_traits<iterator_type>::reference reference;
typedef typename iterator_traits<iterator_type>::iterator_category iterator_category;
private:
iterator_type __i_;
_LIBCPP_HIDE_FROM_ABI _LIBCPP_CONSTEXPR_SINCE_CXX14 __wrap_iter& operator+=(difference_type __n) _NOEXCEPT{
_LIBCPP_DEBUG_ASSERT(__get_const_db()->__addable(this, __n), "Attempted to add/subtract an iterator outside its valid range");
__i_ += __n;
return *this;
}
};
另外需要注意的是vector的end()的返回值就是__end_指向的位置,该位置是一个未知的地址,只能作为结束位置的标识符不能访问对应的内存。
5.3.1.2 list_iterator
list_iterator的实现是和list的实现相关的,是对根据链表的指针访问节点的一个包装,因为链表只能通过当前节点访问前向节点和后向节点,支持随机访问本身意义不大,因此是双向访问节点。实现也比较简单,不详述。
template <class _Tp, class _VoidPtr>
class _LIBCPP_TEMPLATE_VIS __list_iterator
{
typedef __list_node_pointer_traits<_Tp, _VoidPtr> _NodeTraits;
typedef typename _NodeTraits::__link_pointer __link_pointer;
__link_pointer __ptr_;
_LIBCPP_INLINE_VISIBILITY
explicit __list_iterator(__link_pointer __p, const void* __c) _NOEXCEPT
: __ptr_(__p){
(void)__c;
}
template<class, class> friend class list;
template<class, class> friend class __list_imp;
template<class, class> friend class __list_const_iterator;
public:
typedef bidirectional_iterator_tag iterator_category;
typedef _Tp value_type;
typedef value_type& reference;
typedef __rebind_pointer_t<_VoidPtr, value_type> pointer;
typedef typename pointer_traits<pointer>::difference_type difference_type;
__list_iterator& operator++(){
__ptr_ = __ptr_->__next_;
return *this;
}
__list_iterator operator++(int) {__list_iterator __t(*this); ++(*this); return __t;}
__list_iterator& operator--(){
__ptr_ = __ptr_->__prev_;
return *this;
}
}
5.3.1.3 map_iterator
mapSTL内部实现是红黑树,而map_iterator是一个包装器具体的是实现__tree_iterator。比如operator++的实现就是访问平衡数的下一个节点。
template <class _EndNodePtr, class _NodePtr>
inline _LIBCPP_INLINE_VISIBILITY _EndNodePtr __tree_next_iter(_NodePtr __x) _NOEXCEPT{
_LIBCPP_ASSERT(__x != nullptr, "node shouldn't be null");
if (__x->__right_ != nullptr)
return static_cast<_EndNodePtr>(_VSTD::__tree_min(__x->__right_));
while (!_VSTD::__tree_is_left_child(__x))
__x = __x->__parent_unsafe();
return static_cast<_EndNodePtr>(__x->__parent_);
}
而unordered_map的迭代器实现由__hash_table提供,实现比较复杂在了解hash_table的实现时再详细描述。
5.3.2 迭代器包装器
5.3.2.1 reverse_iterator
reverse_iterator是一个迭代器的包装器,,并不是一个真正的迭代器。reverse_iterator可以相对于当前迭代器反方向访问元素,它将当前迭代器的操作方向完全逆转,+变成-,-变成+,不详述,代码比较简单。
template <class _Iter>
class _LIBCPP_TEMPLATE_VIS reverse_iterator
#if _LIBCPP_STD_VER <= 14 || !defined(_LIBCPP_ABI_NO_ITERATOR_BASES)
: public iterator<typename iterator_traits<_Iter>::iterator_category,
typename iterator_traits<_Iter>::value_type,
typename iterator_traits<_Iter>::difference_type,
typename iterator_traits<_Iter>::pointer,
typename iterator_traits<_Iter>::reference>
#endif
{
_LIBCPP_SUPPRESS_DEPRECATED_POP
private:
#ifndef _LIBCPP_ABI_NO_ITERATOR_BASES
_Iter __t_; // no longer used as of LWG #2360, not removed due to ABI break
#endif
#if _LIBCPP_STD_VER >= 20
static_assert(__is_cpp17_bidirectional_iterator<_Iter>::value || bidirectional_iterator<_Iter>,
"reverse_iterator<It> requires It to be a bidirectional iterator.");
#endif // _LIBCPP_STD_VER >= 20
protected:
_Iter current;
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX17
reverse_iterator& operator++() {--current; return *this;}
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX17
reverse_iterator operator++(int) {reverse_iterator __tmp(*this); --current; return __tmp;}
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX17
reverse_iterator& operator--() {++current; return *this;}
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX17
reverse_iterator operator--(int) {reverse_iterator __tmp(*this); ++current; return __tmp;}
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX17
reverse_iterator operator+(difference_type __n) const {return reverse_iterator(current - __n);}
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX17
reverse_iterator& operator+=(difference_type __n) {current -= __n; return *this;}
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX17
reverse_iterator operator-(difference_type __n) const {return reverse_iterator(current + __n);}
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX17
reverse_iterator& operator-=(difference_type __n) {current += __n; return *this;}
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX17
reference operator[](difference_type __n) const {return *(*this + __n);}
};
5.3.2.2 back_inserter、back_insert_iterator、insert_iterator、front_insert_iterator、insert_iterator和inserter
后向插入迭代器,在给back_inserter赋值是就会调用容器的push_back函数插入元素。也就是说只有push_back接口的容器才能使用back_inserter。
_LIBCPP_HIDE_FROM_ABI _LIBCPP_CONSTEXPR_SINCE_CXX20 back_insert_iterator& operator=(const typename _Container::value_type& __value){
container->push_back(__value); return *this;
}
template <class _Container>
inline _LIBCPP_HIDE_FROM_ABI _LIBCPP_CONSTEXPR_SINCE_CXX20 back_insert_iterator<_Container>
back_inserter(_Container& __x){
return back_insert_iterator<_Container>(__x);
}
insert_iterator和front_insert_iterator通过调用容器的push_front函数实现前插。
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX20 front_insert_iterator& operator=(const typename _Container::value_type& __value)
{container->push_front(__value); return *this;}
insert_iterator和inserter通过调用insert函数来实现插入元素。
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX20 insert_iterator& operator=(const typename _Container::value_type& __value)
{iter = container->insert(iter, __value); ++iter; return *this;}
6 deque
deque是STL中的双向队列序列容器,可以在队列的队头和队尾插入或者pop元素。因为限制了操作元素的节点因此操作基本上是常数的。deque的实现相比vector更加复杂,前者采用了多段内存段的实现而不是一整块连续的内存。因此不能假定deque的内存时完全连续的。
6.1 deque_map
C++标准库中的队列实现是一个一个block组成的,并不是一整块连续的内存,每个block内存时连续的,而block的地址存储在__map__中。__map__就是一个序列化容器,类似于vector的内部实现,其内部存储的是每个block的指针,而每个block的指针指向一块连续的内存,每块连续内存的大小是__block_size * sizeof(value_type)。
template <class _ValueType, class _DiffType>
struct __deque_block_size {
static const _DiffType value = sizeof(_ValueType) < 256 ? 4096 / sizeof(_ValueType) : 16;
};

static const difference_type __block_size;
__map __map_;
size_type __start_;
__compressed_pair<size_type, allocator_type> __size_;
因此我们先简单看下__map__的结构,可以看到__map就是一个split_buffer,在vector源码中有用到这个结构但是只是作为size计算的一个中间产物,并没有什么用。
using __map = __split_buffer<pointer, __pointer_allocator>;
split_buffer
template <class _Tp, class _Allocator = allocator<_Tp> >
struct __split_buffer
{
static const difference_type __block_size;
pointer __first_;
pointer __begin_;
pointer __end_;
__compressed_pair<pointer, allocator_type> __end_cap_;
};
split_buffer基本上和vector一致,从construct_to_end的实现可见一斑。稍有不同就是元素起始位置不是容器开头而是__first__,即distance(__first__, __begin__)可能不为0,并且前者会频繁调整元素的位置。
template <class _Tp, class _Allocator>
template <class _InputIter>
_LIBCPP_CONSTEXPR_SINCE_CXX20 __enable_if_t<__is_exactly_cpp17_input_iterator<_InputIter>::value>
__split_buffer<_Tp, _Allocator>::__construct_at_end(_InputIter __first, _InputIter __last)
{
__alloc_rr& __a = this->__alloc();
for (; __first != __last; ++__first)
{
if (__end_ == __end_cap())
{
size_type __old_cap = __end_cap() - __first_;
size_type __new_cap = _VSTD::max<size_type>(2 * __old_cap, 8);
__split_buffer __buf(__new_cap, 0, __a);
for (pointer __p = __begin_; __p != __end_; ++__p, (void) ++__buf.__end_)
__alloc_traits::construct(__buf.__alloc(),
_VSTD::__to_address(__buf.__end_), _VSTD::move(*__p));
swap(__buf);
}
__alloc_traits::construct(__a, _VSTD::__to_address(this->__end_), *__first);
++this->__end_;
}
}
split_buffer会在插入元素时会调整当前元素的位置使得元素始终在整个内存空间的中间,这样能够保证在插入元素时头部和尾部始终由足够的空间进行插入元素,而不至于频繁申请内存。

如果没有足够的空间触发分配内存时的策略也与vector不同,重新分配完之后会将当前使用的空间移动到当前容器的正中间。
void __split_buffer<_Tp, _Allocator>::push_back(const_reference __x)
{
if (__end_ == __end_cap())
{
if (__begin_ > __first_)
{//如果当前容器前半部分由空闲就会将容器内元素前移,push_front刚好相反会将元素后移
difference_type __d = __begin_ - __first_;
__d = (__d + 1) / 2;
__end_ = _VSTD::move(__begin_, __end_, __begin_ - __d);
__begin_ -= __d;
}
else
{
size_type __c = std::max<size_type>(2 * static_cast<size_t>(__end_cap() - __first_), 1);
//push_front的时候这里略有不同
//push_front __split_buffer<value_type, __alloc_rr&> __t(__c, (__c + 3) / 4, __alloc());
__split_buffer<value_type, __alloc_rr&> __t(__c, __c / 4, __alloc()); //开始位置的指针刚好让已用空间在中间
__t.__construct_at_end(move_iterator<pointer>(__begin_),
move_iterator<pointer>(__end_));
_VSTD::swap(__first_, __t.__first_);
_VSTD::swap(__begin_, __t.__begin_);
_VSTD::swap(__end_, __t.__end_);
_VSTD::swap(__end_cap(), __t.__end_cap());
}
}
__alloc_traits::construct(__alloc(), _VSTD::__to_address(__end_), __x);
++__end_;
}
6.2 push_back
直接看下push_back的实现,了解如何插入元素,对deque内存结构也会有完整的认识。流程比较简单就是检查是否有足够的的空间,没有的话就会申请,否则直接在尾部创建。
template <class _Tp, class _Allocator>
void deque<_Tp, _Allocator>::push_back(const value_type& __v)
{
allocator_type& __a = __alloc();
if (__back_spare() == 0)
__add_back_capacity();
// __back_spare() >= 1
__alloc_traits::construct(__a, _VSTD::addressof(*end()), __v);
++__size();
}
从deque的size相关的函数实现我们能够大致判断内存结构,可以看到__start__指向的是当前队列的开头,而这个值时相对于整个队里的大小,即取值范围为[0 , block() * __block_size__ - 1]。通过__start__,__block_size__,__map__.size(),__size_就可以计算处当前队列中的尾部以及元素的数量。
size_type __capacity() const{
return __map_.size() == 0 ? 0 : __map_.size() * __block_size - 1;
}
size_type __block_count() const{
return __map_.size();
}
size_type __front_spare() const{
return __start_;
}
size_type __front_spare_blocks() const {
return __front_spare() / __block_size;
}
size_type __back_spare() const{
return __capacity() - (__start_ + size());
}
size_type __back_spare_blocks() const {
return __back_spare() / __block_size;
}
从上面我们能大致看出deque的内存结构:

从上面的代码中能够看出针对三种情况进行了不同的处理:
当队列前有整块block时,直接将前面的block移动到后面,这样就不用重新分配内存了;
当map头部仍然头未使用的block时,直接分配新的block尾插;
如果
split_buffer尾部有空间则直接allocate新的block;如果
split_buffer尾部没有空间就先头差再pop尾插,这样能够确保已经使用的空间刚好在split_buffer的正中间,也不会带来额外的开销;
当map内完全没有空闲空间时,重新整块map;

template <class _Tp, class _Allocator>
void
deque<_Tp, _Allocator>::__add_back_capacity()
{
allocator_type& __a = __alloc();
if (__front_spare() >= __block_size){ //队列头有整块block
__start_ -= __block_size;
pointer __pt = __map_.front();
__map_.pop_front();
__map_.push_back(__pt);
}
// Else if __nb <= __map_.capacity() - __map_.size() then we need to allocate __nb buffers
else if (__map_.size() < __map_.capacity())
{ // we can put the new buffer into the map, but don't shift things around
// until it is allocated. If we throw, we don't need to fix
// anything up (any added buffers are undetectible)
if (__map_.__back_spare() != 0) //__map__的尾部还有足够的空间push_back不会触发新分配内存直接插入
__map_.push_back(__alloc_traits::allocate(__a, __block_size));
else{
//这里这样做是为了让可用空间刚好在split_buffer的正中间
__map_.push_front(__alloc_traits::allocate(__a, __block_size));
// Done allocating, reorder capacity
pointer __pt = __map_.front();
__map_.pop_front();
__map_.push_back(__pt);
}
}
// Else need to allocate 1 buffer, *and* we need to reallocate __map_.
else{//重新分配整块map
__split_buffer<pointer, __pointer_allocator&>
__buf(std::max<size_type>(2* __map_.capacity(), 1),
__map_.size(),
__map_.__alloc());
typedef __allocator_destructor<_Allocator> _Dp;
unique_ptr<pointer, _Dp> __hold(
__alloc_traits::allocate(__a, __block_size),
_Dp(__a, __block_size));
__buf.push_back(__hold.get());
__hold.release();
for (__map_pointer __i = __map_.end();
__i != __map_.begin();)
__buf.push_front(*--__i);
_VSTD::swap(__map_.__first_, __buf.__first_);
_VSTD::swap(__map_.__begin_, __buf.__begin_);
_VSTD::swap(__map_.__end_, __buf.__end_);
_VSTD::swap(__map_.__end_cap(), __buf.__end_cap());
}
}
push_front的逻辑基本相同,只不过方向相反。emplace_back和push_back的逻辑上是一样的,唯一的区别是对象构建的时机和vector中二者的差别相同。
6.3 pop_front
pop_front实现比较简单就是析构对应点的对象。
template <class _Tp, class _Allocator>
void deque<_Tp, _Allocator>::pop_front(){
allocator_type& __a = __alloc();
__alloc_traits::destroy(__a, _VSTD::__to_address(*(__map_.begin() +
__start_ / __block_size) +
__start_ % __block_size));
--__size();
++__start_;
__maybe_remove_front_spare();
}
如果队列中空闲的比较多就会尝试回收,这里的阈值是2个block。
bool __maybe_remove_front_spare(bool __keep_one = true) {
if (__front_spare_blocks() >= 2 || (!__keep_one && __front_spare_blocks())) {
__alloc_traits::deallocate(__alloc(), __map_.front(),
__block_size);
__map_.pop_front();
__start_ -= __block_size;
return true;
}
return false;
}
6.4 迭代器
deque的迭代器时__deque_iterator。
using iterator = __deque_iterator<value_type, pointer, reference, __map_pointer, difference_type>;
因为deque是非连续内存,因此deque_iterator需要对一些节点计算进行处理。deque_iterator中包含一个__m_iter_就是一个队列中map的普通指针。__m_iter_表示当前迭代器指向的map节点,而__ptr_表示当前队列中元素在当前block的位置。
class _LIBCPP_TEMPLATE_VIS __deque_iterator{
typedef _MapPointer __map_iterator;
public:
typedef _Pointer pointer;
typedef _DiffType difference_type;
private:
__map_iterator __m_iter_;
pointer __ptr_;
static const difference_type __block_size;
};
我们简单看下迭代器如何自增和自减。从下面的实现可以看出就是进行简单的游标标记,如果当前指针超过当前block则map自增。dequeue也是相同的道理,先计算block的索引,再根据block内的索引来计算具体的位置。
//deque_iterator
_LIBCPP_HIDE_FROM_ABI __deque_iterator& operator++(){
if (++__ptr_ - *__m_iter_ == __block_size)
{
++__m_iter_;
__ptr_ = *__m_iter_;
}
return *this;
}
//deque
_LIBCPP_HIDE_FROM_ABI iterator begin() _NOEXCEPT {
__map_pointer __mp = __map_.begin() + __start_ / __block_size;
return iterator(__mp, __map_.empty() ? 0 : *__mp + __start_ % __block_size);
}
根据上面的代码可以看出一个deque的内存布局。

7 forward_list
forward_list是STL中的单向链表序列容器,可以在任意位置快速插入(前提是直到期望插入的位置),不支持快速的随机访问。需要注意的是因为forward_list是单向链表也就意味着size相关的函数可能是O(1)的。
forward_list的定义如下:
template <class _Tp, class _Alloc /*= allocator<_Tp>*/>
class _LIBCPP_TEMPLATE_VIS forward_list : private __forward_list_base<_Tp, _Alloc>{
};
7.1 __forward_list_base

forward_list是基于__forward_list_base实现的,其中只有一个头结点。
template <class _Tp, class _Alloc>
class __forward_list_base{
protected:
__compressed_pair<__begin_node, __node_allocator> __before_begin_;
};
7.1.1 节点
链表中由两种节点,一种是__begin_node是链表的头结点,另一种是__node是链表内数据成员的节点,其存储链表中保存的数据。
typedef __forward_list_node<value_type, void_pointer> __node;
typedef __begin_node_of<value_type, void_pointer> __begin_node;
二者的区别就是将索引和值域区分了开来。从下面的代码可以看出__begin_node就是一个指针的adapter,而__forward_list_node和我们常见的链表节点没什么区别。这样做的好处是在使用迭代器时只需要一个指针的空间就可以表示索引,而不用每个迭代器都携带一个没用的value域,浪费空间。
template <class _NodePtr>
struct __forward_begin_node{
typedef _NodePtr pointer;
typedef __rebind_pointer_t<_NodePtr, __forward_begin_node> __begin_node_pointer;
pointer __next_;
_LIBCPP_INLINE_VISIBILITY __forward_begin_node() : __next_(nullptr) {}
__begin_node_pointer __next_as_begin() const {
return static_cast<__begin_node_pointer>(__next_);
}
};
template <class _Tp, class _VoidPtr>
using __begin_node_of = __forward_begin_node<__rebind_pointer_t<_VoidPtr, __forward_list_node<_Tp, _VoidPtr> > >;
template <class _Tp, class _VoidPtr>
struct _LIBCPP_STANDALONE_DEBUG __forward_list_node : public __begin_node_of<_Tp, _VoidPtr>{
typedef _Tp value_type;
value_type __value_;
};
7.1.2 __forward_list_base
__forward_list_base就是存储了一个节点__before_begin_,简单封装了一些拷贝和move的函数,唯一有点儿代码的就是clear(),代码也比较简单就是用for-loop析构对象释放节点的内存。
template <class _Tp, class _Alloc>
void __forward_list_base<_Tp, _Alloc>::clear() _NOEXCEPT{
__node_allocator& __a = __alloc();
for (__node_pointer __p = __before_begin()->__next_; __p != nullptr;){
__node_pointer __next = __p->__next_;
__node_traits::destroy(__a, _VSTD::addressof(__p->__value_));
__node_traits::deallocate(__a, __p, 1);
__p = __next;
}
__before_begin()->__next_ = nullptr;
}
7.2 forward_list
7.2.1 迭代器
在了解具体实现前明白迭代器是如何实现的可以帮助我们理解内存布局方式。forward_list迭代器的实现比较简单就是一个__forward_list_node的指针。
template <class _NodePtr>
class _LIBCPP_TEMPLATE_VIS __forward_list_iterator{
//__forward_list_node *
__iter_node_pointer __ptr_;
};
因为是单项链表因此只支持一种方向的索引,实现也比较简单就是当前节点的next指针。
__forward_list_iterator& operator++(){
__ptr_ = __traits::__as_iter_node(__ptr_->__next_);
return *this;
}
7.2.2 forward_list
forward_list是继承自__forward_list_base
template <class _Tp, class _Alloc /*= allocator<_Tp>*/>
class _LIBCPP_TEMPLATE_VIS forward_list : private __forward_list_base<_Tp, _Alloc>{};
因为是单向链表因此只允许头插,实现也比较简单就是创建节点,然后将对应的指针指向对应的节点。
template <class _Tp, class _Alloc>
void forward_list<_Tp, _Alloc>::push_front(value_type&& __v){
__node_allocator& __a = base::__alloc();
typedef __allocator_destructor<__node_allocator> _Dp;
unique_ptr<__node, _Dp> __h(__node_traits::allocate(__a, 1), _Dp(__a, 1));
__node_traits::construct(__a, _VSTD::addressof(__h->__value_), _VSTD::move(__v));
__h->__next_ = base::__before_begin()->__next_;
base::__before_begin()->__next_ = __h.release();
}
template <class _Tp, class _Alloc>
void forward_list<_Tp, _Alloc>::pop_front()
{
__node_allocator& __a = base::__alloc();
__node_pointer __p = base::__before_begin()->__next_;
base::__before_begin()->__next_ = __p->__next_;
__node_traits::destroy(__a, _VSTD::addressof(__p->__value_));
__node_traits::deallocate(__a, __p, 1);
}
template <class _Tp, class _Alloc>
typename forward_list<_Tp, _Alloc>::iterator
forward_list<_Tp, _Alloc>::insert_after(const_iterator __p, const value_type& __v){
__begin_node_pointer const __r = __p.__get_begin();
__node_allocator& __a = base::__alloc();
typedef __allocator_destructor<__node_allocator> _Dp;
unique_ptr<__node, _Dp> __h(__node_traits::allocate(__a, 1), _Dp(__a, 1));
__node_traits::construct(__a, _VSTD::addressof(__h->__value_), __v);
__h->__next_ = __r->__next_;
__r->__next_ = __h.release();
return iterator(__r->__next_);
}
其他几个函数的实现都是改变节点之类的比较简单就不详细描述了。
8 list
前言:之前看过侯老师的《STL源码剖析》但是那已经是多年以前的,现在工作中有时候查问题和崩溃都需要了解实际工作中使用到的STL的实现。因此计划把STL的源码再过一遍。
摘要:本文描述了llvm中libcxx的list的实现。
关键字:list
其他:参考代码LLVM-libcxx
注意:参考代码时llvm的实现,与gnu和msvc的实现都有区别。
list是STL提供的双向链表,可以在头和尾部操作元素。

8.1 节点
和forward_list一样,list针对索引和节点进行了区分,索引只包含对应访问节点的指针,而节点同时包含链接的指针和数据成员。
template <class _Tp, class _VoidPtr>
struct __list_node_base{
typedef __list_node_pointer_traits<_Tp, _VoidPtr> _NodeTraits;
typedef typename _NodeTraits::__link_pointer __link_pointer;
__link_pointer __prev_; //前向指针
__link_pointer __next_; //后向指针
};
template <class _Tp, class _VoidPtr>
struct _LIBCPP_STANDALONE_DEBUG __list_node : public __list_node_base<_Tp, _VoidPtr>{
_Tp __value_;
};
8.2 迭代器
list的迭代器就是一个list_node的指针,其自增和自减的操作实现也比较简单就是访问node的前向和后向连接的指针。
template <class _Tp, class _VoidPtr>
class _LIBCPP_TEMPLATE_VIS __list_iterator{
typedef __list_node_pointer_traits<_Tp, _VoidPtr> _NodeTraits;
typedef typename _NodeTraits::__link_pointer __link_pointer;
__link_pointer __ptr_;
__list_iterator& operator++(){
_LIBCPP_DEBUG_ASSERT(__get_const_db()->__dereferenceable(this),
"Attempted to increment a non-incrementable list::iterator");
__ptr_ = __ptr_->__next_;
return *this;
}
__list_iterator& operator--(){
_LIBCPP_DEBUG_ASSERT(__get_const_db()->__decrementable(this),
"Attempted to decrement a non-decrementable list::iterator");
__ptr_ = __ptr_->__prev_;
return *this;
}
};
8.3 list实现
list的内存布局由__list_impl描述,成员__end_作为索引节点描述当前链表的头尾。__end_的next和prev两个指针分别指向链表的头和尾节点,__size_alloc_则保存了当前链表的长度。
template <class _Tp, class _Alloc>
class __list_imp{
__node_base __end_;
__compressed_pair<size_type, __node_allocator> __size_alloc_;
iterator begin() _NOEXCEPT{
return iterator(__end_.__next_, this);
}
iterator end() _NOEXCEPT{
return iterator(__end_as_link(), this);
}
};
而节点的操作就是比较典型的双链表的操作,没什么好说的。clear操作时通过for-loop来遍历每个节点并销毁对应的节点对象以及内存来实现的。
template <class _Tp, class _Alloc>
void __list_imp<_Tp, _Alloc>::clear() _NOEXCEPT{
if (!empty()){
__node_allocator& __na = __node_alloc();
__link_pointer __f = __end_.__next_;
__link_pointer __l = __end_as_link();
__unlink_nodes(__f, __l->__prev_);
__sz() = 0;
while (__f != __l){
__node_pointer __np = __f->__as_node();
__f = __f->__next_;
__node_alloc_traits::destroy(__na, _VSTD::addressof(__np->__value_));
__node_alloc_traits::deallocate(__na, __np, 1);
}
std::__debug_db_invalidate_all(this);
}
}
list就是在__list_impl的基础上封装了常见的链表操作。
template <class _Tp, class _Alloc /*= allocator<_Tp>*/>
class _LIBCPP_TEMPLATE_VIS list : private __list_imp<_Tp, _Alloc>{};
我们就简单看下push_back和pop_back咋实现的(其实就是简单的链表节点的插入)。
push_back首先创建内存在对应的内存上构造输入的对象,然后将节点插入到尾部,节点插入也比较简单就是一般的双链表节点操作,不详述。
template <class _Tp, class _Alloc>
void list<_Tp, _Alloc>::push_back(const value_type& __x){
__node_allocator& __na = base::__node_alloc();
__hold_pointer __hold = __allocate_node(__na);
__node_alloc_traits::construct(__na, _VSTD::addressof(__hold->__value_), __x);
__link_nodes_at_back(__hold.get()->__as_link(), __hold.get()->__as_link());
++base::__sz();
__hold.release();
}
template <class _Tp, class _Alloc>
inline void list<_Tp, _Alloc>::__link_nodes_at_back(__link_pointer __f, __link_pointer __l){
__l->__next_ = base::__end_as_link();
__f->__prev_ = base::__end_.__prev_;
__f->__prev_->__next_ = __f;
base::__end_.__prev_ = __l;
}
pop_front的实现也比较简单直观,不详细描述。
template <class _Tp, class _Alloc>
void list<_Tp, _Alloc>::pop_front(){
_LIBCPP_ASSERT(!empty(), "list::pop_front() called with empty list");
__node_allocator& __na = base::__node_alloc();
__link_pointer __n = base::__end_.__next_;
base::__unlink_nodes(__n, __n);
--base::__sz();
__node_pointer __np = __n->__as_node();
__node_alloc_traits::destroy(__na, _VSTD::addressof(__np->__value_));
__node_alloc_traits::deallocate(__na, __np, 1);
}
template <class _Tp, class _Alloc>
inline void __list_imp<_Tp, _Alloc>::__unlink_nodes(__link_pointer __f, __link_pointer __l)_NOEXCEPT{
__f->__prev_->__next_ = __l->__next_;
__l->__next_->__prev_ = __f->__prev_;
}
9 容器适配器
C++中有三种常用的容器,本身并不是一个容器而是适配器,即其实际的利用已有的容器实现的对应容器的功能。
stack提供了FILO(先入后出)的能力。queue提供了FIFO的能力。priority_queue优先队列。
9.1 stack
stack在STL中的实现默认是通过deque,当然也可以指定容器,但是前提是对应的容器包含某些操作接口。说stack是适配器也可以看到,该类里面就是包装了另一个容器,然后利用该容器的接口实现需要的功能。如果期望使用自定义的容器,对应的容器应该支持pop_back(), push_back(), size(), empty()等接口。
template <class _Tp, class _Container /*= deque<_Tp>*/>
class _LIBCPP_TEMPLATE_VIS stack{
public:
typedef _Container container_type;
typedef typename container_type::value_type value_type;
typedef typename container_type::reference reference;
typedef typename container_type::const_reference const_reference;
typedef typename container_type::size_type size_type;
static_assert((is_same<_Tp, value_type>::value), "" );
protected:
container_type c;
};
stack的实现比较简单,没什么好说的。需要注意的是top和pop分开实现了而不是直接一个接口实现是为了保证异常安全。如果在同一个接口中实现,当获取元素时正常,pop完数据,返回过程中拷贝数据对象时发生异常数据就会丢失。
void push(const value_type& __v) {c.push_back(__v);}
const_reference top() const {return c.back();}
void pop() {c.pop_back();}
9.2 queue
queue和stack定义相同默认都是包装了一个deque
template <class _Tp, class _Container /*= deque<_Tp>*/>
class _LIBCPP_TEMPLATE_VIS queue{
public:
typedef _Container container_type;
typedef typename container_type::value_type value_type;
typedef typename container_type::reference reference;
typedef typename container_type::const_reference const_reference;
typedef typename container_type::size_type size_type;
static_assert((is_same<_Tp, value_type>::value), "" );
protected:
container_type c;
};
deque的实现也非常简单,不多描述。
bool empty() const {return c.empty();}
_LIBCPP_INLINE_VISIBILITY
size_type size() const {return c.size();}
_LIBCPP_INLINE_VISIBILITY
reference front() {return c.front();}
_LIBCPP_INLINE_VISIBILITY
const_reference front() const {return c.front();}
_LIBCPP_INLINE_VISIBILITY
reference back() {return c.back();}
_LIBCPP_INLINE_VISIBILITY
const_reference back() const {return c.back();}
_LIBCPP_INLINE_VISIBILITY
void push(const value_type& __v) {c.push_back(__v);}
9.3 priority_queue
优先队列就是一个堆,容器内数据某种程度上是有序的。优先队列的实现和前两者有些差别,默认是vector,因为容器内元素是某种程度上有序的,所以需要提供比较函数。
template <class _Tp, class _Container = vector<_Tp>, class _Compare = less<typename _Container::value_type> >
class _LIBCPP_TEMPLATE_VIS priority_queue{
public:
typedef _Container container_type;
typedef _Compare value_compare;
typedef typename container_type::value_type value_type;
typedef typename container_type::reference reference;
typedef typename container_type::const_reference const_reference;
typedef typename container_type::size_type size_type;
static_assert((is_same<_Tp, value_type>::value), "" );
protected:
container_type c;
value_compare comp;
};
在构造堆时会调用std::make_heap在当前容器上创建堆。现在不详细具体的实现,等看算法实现时再详细描述(估计是一般的堆构造算法)。
template <class _Tp, class _Container, class _Compare>
inline priority_queue<_Tp, _Container, _Compare>::priority_queue(const value_compare& __comp, container_type&& __c)
: c(_VSTD::move(__c)),
comp(__comp){
_VSTD::make_heap(c.begin(), c.end(), comp);
}
插入和弹出元素也都调用的是std的算法实现。
template <class _Tp, class _Container, class _Compare>
inline void priority_queue<_Tp, _Container, _Compare>::push(value_type&& __v){
c.push_back(_VSTD::move(__v));
_VSTD::push_heap(c.begin(), c.end(), comp);
}
template <class _Tp, class _Container, class _Compare>
inline void priority_queue<_Tp, _Container, _Compare>::pop(){
_VSTD::pop_heap(c.begin(), c.end(), comp);
c.pop_back();
}
10 map和set
map是STL中的关联容器,和vector等的序列容器不同,其内存结构无论是逻辑还是物理上都不是线性的。map通过键值对存储元素,每个key是唯一的。因为map是用红黑树实现的,因此map的查找效率是很高的,基本可以保证在O(logn)的时间复杂度内进行查找、插入,删除等操作。
map的实现是通过红黑树实现的,在STL中就是__tree。因此我们理解了__tree的实现之后基本上能够明白map细节的90%。
typedef __tree<__value_type, __vc, __allocator_type> __base;
10.1 树
10.1.1 节点
和一般的STL对象一样,树节点通过__tree_node_types描述对应节点的各种类型,这里不详细描述。
树节点就是常规的节点,每个节点包含两个子节点指针,一个父节点指针以及一个表示当前根节点的颜色的标志位。这里将值域和索引的指针进行了区分,而不是存在在同一个类里。另外__tree_node节点的析构函数是声明为delete的,其析构是通过__tree_node_destructor实现的,__tre_node_destructor的实现比较简单就是根据当前节点是否构造来选择释放内存还是析构对象。
template <class _Pointer>
class __tree_end_node{
public:
typedef _Pointer pointer;
pointer __left_;
};
template <class _VoidPtr>
class _LIBCPP_STANDALONE_DEBUG __tree_node_base : public __tree_node_base_types<_VoidPtr>::__end_node_type{
typedef __tree_node_base_types<_VoidPtr> _NodeBaseTypes;
pointer __right_;
__parent_pointer __parent_;
bool __is_black_;
};
template <class _Tp, class _VoidPtr>
class _LIBCPP_STANDALONE_DEBUG __tree_node : public __tree_node_base<_VoidPtr>{
public:
typedef _Tp __node_value_type;
__node_value_type __value_;
private:
~__tree_node() = delete;
__tree_node(__tree_node const&) = delete;
__tree_node& operator=(__tree_node const&) = delete;
};
//树节点的析构器
template <class _Allocator>
class __tree_node_destructor{
public:
bool __value_constructed;
__tree_node_destructor(const __tree_node_destructor &) = default;
__tree_node_destructor& operator=(const __tree_node_destructor&) = delete;
explicit __tree_node_destructor(allocator_type& __na, bool __val = false) _NOEXCEPT : __na_(__na), __value_constructed(__val){}
void operator()(pointer __p) _NOEXCEPT{
if (__value_constructed)
__alloc_traits::destroy(__na_, _NodeTypes::__get_ptr(__p->__value_));
if (__p)
__alloc_traits::deallocate(__na_, __p, 1);
}
};
10.1.2 树迭代器
树的迭代器就是一个节点的指针,节点操作的方式就是红黑树的基本操作方式。
//定义在__tree_node_types中
typedef __conditional_t< is_pointer<__node_pointer>::value, typename __base::__end_node_pointer, __node_pointer>
__iter_pointer;
template <class _Tp, class _NodePtr, class _DiffType>
class _LIBCPP_TEMPLATE_VIS __tree_iterator{
typedef typename _NodeTypes::__iter_pointer __iter_pointer;
__iter_pointer __ptr_;
}
这里简单看下++的操作,--类似。平衡树的下一个节点应该是其中序遍历的下一个节点:
如果当前节点为父节点的左节点,则下一个节点为父节点;
如果当前节点为父节点的右节点:
且其右子节点不为空,则下一个节点为右子树的最小节点(最左子节点);
若右子节点为空,则向上递归找到祖先节点中是其父节点的右子节点的节点;
template <class _EndNodePtr, class _NodePtr>
inline _LIBCPP_INLINE_VISIBILITY _EndNodePtr __tree_next_iter(_NodePtr __x) _NOEXCEPT{
_LIBCPP_ASSERT(__x != nullptr, "node shouldn't be null");
if (__x->__right_ != nullptr) //情况2
return static_cast<_EndNodePtr>(_VSTD::__tree_min(__x->__right_));
while (!_VSTD::__tree_is_left_child(__x))//情况2和情况3
__x = __x->__parent_unsafe();
return static_cast<_EndNodePtr>(__x->__parent_);
}
10.1.3 树
STL中树的实现是__tree,因为是有序的容器因此用户需要提供一个比较器(默认就是==)。__tree中有两个节点,开始节点和结束节点,一个分配器,和当前数的节点数以及比较器。树的顺序是按照中序排列的,开始节点即整棵树的最左子节点就是__begin_node_,根节点就是__pair1_.first()->left,尾结点即最右子节点就是__pair1_.first()。
template <class _Tp, class _Compare, class _Allocator>
class __tree{
__iter_pointer __begin_node_;
__compressed_pair<__end_node_t, __node_allocator> __pair1_;
__compressed_pair<size_type, value_compare> __pair3_;
};
树为空时__begin_node == __end_node
树中针对重复元素和唯一元素实现了不同的接口,这样是为了同时支持map和multmap。
iterator __insert_unique(const_iterator __p, _Vp&& __v) {
return __emplace_hint_unique(__p, _VSTD::forward<_Vp>(__v));
}
iterator __insert_multi(__container_value_type&& __v) {
return __emplace_multi(_VSTD::move(__v));
}
__emplace_hint_unique
__emplace_hint_unique用于向当前树中插入一个节点,其基本步骤是:
构造节点;
在树中查找是否存在相同key的节点;
将节点插入树中。
template <class _Tp, class _Compare, class _Allocator>
template <class... _Args>
typename __tree<_Tp, _Compare, _Allocator>::iterator
__tree<_Tp, _Compare, _Allocator>::__emplace_hint_unique_impl(const_iterator __p, _Args&&... __args){
__node_holder __h = __construct_node(_VSTD::forward<_Args>(__args)...);
__parent_pointer __parent;
__node_base_pointer __dummy;
__node_base_pointer& __child = __find_equal(__p, __parent, __dummy, __h->__value_);
__node_pointer __r = static_cast<__node_pointer>(__child);
if (__child == nullptr)
{
__insert_node_at(__parent, __child, static_cast<__node_base_pointer>(__h.get()));
__r = __h.release();
}
return iterator(__r);
}
下面我们一步一步看,构造节点就是调用construct_node实现的,在树中查找节点是通过__find_equal实现的。__find_equal的实现比较简单就是通过非递归中序遍历的过程。其中value_comp是自定义的比较函数对象,默认是lesser。需要注意的是
template <class _Tp, class _Compare, class _Allocator>
template <class _Key>
typename __tree<_Tp, _Compare, _Allocator>::__node_base_pointer& __tree<_Tp, _Compare, _Allocator>::__find_equal(__parent_pointer& __parent, const _Key& __v){
__node_pointer __nd = __root();
__node_base_pointer* __nd_ptr = __root_ptr();
if (__nd != nullptr){
while (true){
if (value_comp()(__v, __nd->__value_)){
if (__nd->__left_ != nullptr) {
__nd_ptr = _VSTD::addressof(__nd->__left_);
__nd = static_cast<__node_pointer>(__nd->__left_);
} else {
__parent = static_cast<__parent_pointer>(__nd);
return __parent->__left_;
}
}
else if (value_comp()(__nd->__value_, __v)){
if (__nd->__right_ != nullptr) {
__nd_ptr = _VSTD::addressof(__nd->__right_);
__nd = static_cast<__node_pointer>(__nd->__right_);
} else {
__parent = static_cast<__parent_pointer>(__nd);
return __nd->__right_;
}
}
else{
__parent = static_cast<__parent_pointer>(__nd);
return *__nd_ptr;
}
}
}
__parent = static_cast<__parent_pointer>(__end_node());
return __parent->__left_;
}
找到要插入的位置,我们看下是如何插入的。基本过程是先插入节点到预定的位置,然后检查节点与父节点的颜色是否正确,如果不正确就会对树进行调整。插入是通过__insert_node_at实现的。
template <class _Tp, class _Compare, class _Allocator>
void __tree<_Tp, _Compare, _Allocator>::__insert_node_at( __parent_pointer __parent, __node_base_pointer& __child, __node_base_pointer __new_node) _NOEXCEPT{
__new_node->__left_ = nullptr;
__new_node->__right_ = nullptr;
__new_node->__parent_ = __parent;
// __new_node->__is_black_ is initialized in __tree_balance_after_insert
__child = __new_node;
if (__begin_node()->__left_ != nullptr)
__begin_node() = static_cast<__iter_pointer>(__begin_node()->__left_);
_VSTD::__tree_balance_after_insert(__end_node()->__left_, __child);
++size();
}
template <class _NodePtr>
_LIBCPP_HIDE_FROM_ABI void
__tree_balance_after_insert(_NodePtr __root, _NodePtr __x) _NOEXCEPT{
_LIBCPP_ASSERT(__root != nullptr, "Root of the tree shouldn't be null");
_LIBCPP_ASSERT(__x != nullptr, "Can't attach null node to a leaf");
__x->__is_black_ = __x == __root;
while (__x != __root && !__x->__parent_unsafe()->__is_black_){
// __x->__parent_ != __root because __x->__parent_->__is_black == false
if (_VSTD::__tree_is_left_child(__x->__parent_unsafe())){
_NodePtr __y = __x->__parent_unsafe()->__parent_unsafe()->__right_;
if (__y != nullptr && !__y->__is_black_){
//新插入的节点改变了整棵树的颜色数量,需要对颜色进行改变
__x = __x->__parent_unsafe();
__x->__is_black_ = true;
__x = __x->__parent_unsafe();
__x->__is_black_ = __x == __root;
__y->__is_black_ = true;
}else{
//如果插入的位置是左子节点的右节点需要先左旋转,再右旋转,否则只需要右旋转
if (!_VSTD::__tree_is_left_child(__x)){
__x = __x->__parent_unsafe();
_VSTD::__tree_left_rotate(__x);
}
__x = __x->__parent_unsafe();
__x->__is_black_ = true;
__x = __x->__parent_unsafe();
__x->__is_black_ = false;
_VSTD::__tree_right_rotate(__x);
break;
}
}
else{
_NodePtr __y = __x->__parent_unsafe()->__parent_->__left_;
if (__y != nullptr && !__y->__is_black_){
//新插入的节点改变了整棵树的颜色数量,需要对颜色进行改变
__x = __x->__parent_unsafe();
__x->__is_black_ = true;
__x = __x->__parent_unsafe();
__x->__is_black_ = __x == __root;
__y->__is_black_ = true;
}else{
//如果插入的位置是右子节点的左节点需要先右旋转,再左旋转,否则只需要左旋转
if (_VSTD::__tree_is_left_child(__x)){
__x = __x->__parent_unsafe();
_VSTD::__tree_right_rotate(__x);
}
__x = __x->__parent_unsafe();
__x->__is_black_ = true;
__x = __x->__parent_unsafe();
__x->__is_black_ = false;
_VSTD::__tree_left_rotate(__x);
break;
}
}
}
}
__emplace_hint_multi
__emplace_hint_multi和__emplace_hint_unique的区别就是搜索插入节点的方式。
template <class _Tp, class _Compare, class _Allocator>
template <class... _Args>
typename __tree<_Tp, _Compare, _Allocator>::iterator __tree<_Tp, _Compare, _Allocator>::__emplace_hint_multi(const_iterator __p, _Args&&... __args){
__node_holder __h = __construct_node(_VSTD::forward<_Args>(__args)...);
__parent_pointer __parent;
__node_base_pointer& __child = __find_leaf(__p, __parent, _NodeTypes::__get_key(__h->__value_));
__insert_node_at(__parent, __child, static_cast<__node_base_pointer>(__h.get()));
return iterator(static_cast<__node_pointer>(__h.release()));
}
10.2 pair
STL中通过std::pair<key, value>来表示key——value键值对。实现比较简单,不同于compressed_pair。
template <class _T1, class _T2>
struct _LIBCPP_TEMPLATE_VIS pair
#if defined(_LIBCPP_DEPRECATED_ABI_DISABLE_PAIR_TRIVIAL_COPY_CTOR)
: private __non_trivially_copyable_base<_T1, _T2>
#endif
{
_T1 first;
_T2 second;
};
10.3 map和multimap
map和multimap的实现基本差不多,区别是是否允许重复元素。
template <class _Key, class _Tp, class _Compare = less<_Key>, class _Allocator = allocator<pair<const _Key, _Tp> > >
class _LIBCPP_TEMPLATE_VIS map{
public:
typedef _Key key_type;
typedef _Tp mapped_type;
typedef pair<const key_type, mapped_type> value_type;
private:
__base __tree_;
};
template <class _Key, class _Tp, class _Compare, class _Allocator>
_Tp& map<_Key, _Tp, _Compare, _Allocator>::operator[](const key_type& __k){
return __tree_.__emplace_unique_key_args(__k,
_VSTD::piecewise_construct,
_VSTD::forward_as_tuple(__k),
_VSTD::forward_as_tuple()).first->__get_value().second;
}
template <class _Key, class _Tp, class _Compare = less<_Key>, class _Allocator = allocator<pair<const _Key, _Tp> > >
class _LIBCPP_TEMPLATE_VIS multimap{
public:
typedef _Key key_type;
typedef _Tp mapped_type;
typedef pair<const key_type, mapped_type> value_type;
private:
__base __tree_;
};
template <class ..._Args>
_LIBCPP_INLINE_VISIBILITY
iterator emplace(_Args&& ...__args) {
return __tree_.__emplace_multi(_VSTD::forward<_Args>(__args)...);
}
10.4 set和multiset
set和map的区别就是其内部的值不同,set仅仅存储key。其实现和map相同都是红黑树,只是存储的内容不同。set和multiset的区别与map和multimap的区别相同,都是是否允许出现重复key。
template <class _Key, class _Compare = less<_Key>, class _Allocator = allocator<_Key> >
class _LIBCPP_TEMPLATE_VIS set{
public:
typedef _Key key_type;
typedef key_type value_type;
static_assert((is_same<typename allocator_type::value_type, value_type>::value),
"Allocator::value_type must be same type as value_type");
private:
typedef __tree<value_type, value_compare, allocator_type> __base;
__base __tree_;
public:
iterator insert(const_iterator __p, const value_type& __v)
{return __tree_.__insert_unique(__p, __v);}
}
template <class _Key, class _Compare = less<_Key>,class _Allocator = allocator<_Key> >
class _LIBCPP_TEMPLATE_VIS multiset{
public:
typedef _Key key_type;
typedef key_type value_type;
private:
typedef __tree<value_type, value_compare, allocator_type> __base;
__base __tree_;
public:
iterator insert(const value_type& __v)
{return __tree_.__insert_multi(__v);}
};
11 unordered_map和unordered_set
unordered_map和unordered_set是是STL提供的无序的容器,二者都是通过哈希表实现的。
11.1 哈希表
11.1.1 __hash_table

STL中的哈希表实现是通过链式实现的,表中有一个数组,数组的每个成员是一个单链表的节点,一个hash值对应一个链表。
__bucket_list_就是一个链表数组,数组的成员是__hash_node_base的指针。__p1_存储第一个元素的指针和分配器(__p1_就是一个完整链表的头结点,哈希表可以通过__p1_访问到每一个元素),__p2__为哈希表中元素的数量和哈希函数,__p3__为当前哈希表数据的紧缩程度(默认1.0),插入元素时会根据这个值决定是否需要对当前表记性rehash。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
class __hash_table{
typedef _Tp value_type;
typedef _Hash hasher;
typedef typename _NodeTypes::__next_pointer __next_pointer;
typedef typename _NodeTypes::__node_base_type __first_node;
typedef unique_ptr<__next_pointer[], __bucket_list_deleter> __bucket_list;
// --- Member data begin ---
__bucket_list __bucket_list_;
__compressed_pair<__first_node, __node_allocator> __p1_;
__compressed_pair<size_type, hasher> __p2_;
__compressed_pair<float, key_equal> __p3_;
};
__hash_node_base
和STL中其他节点的实现相同,哈希表的节点的索引和值域被拆分了开来,分别为__hash_node_base和__hash_node。__bucket_list_就是一个__hash_node_base的数组。
template <class _NodePtr>
struct __hash_node_base{
typedef __hash_node_base __first_node;
typedef __rebind_pointer_t<_NodePtr, __first_node> __node_base_pointer;
typedef _NodePtr __node_pointer;
#if defined(_LIBCPP_ABI_FIX_UNORDERED_NODE_POINTER_UB)
typedef __node_base_pointer __next_pointer;
#else
typedef __conditional_t<is_pointer<__node_pointer>::value, __node_base_pointer, __node_pointer> __next_pointer;
#endif
__next_pointer __next_;
};
template <class _Tp, class _VoidPtr>
struct _LIBCPP_STANDALONE_DEBUG __hash_node: public __hash_node_base<__rebind_pointer_t<_VoidPtr, __hash_node<_Tp, _VoidPtr> >>{
typedef _Tp __node_value_type;
size_t __hash_;
__node_value_type __value_;
};
__bucket_list
我们从__bucket_list的声明中能够看出其就是一个智能指针,其大小保存在自身的销毁器__bucket_list_deallocator中。
typedef unique_ptr<__next_pointer[], __bucket_list_deleter> __bucket_list;
template <class _Alloc>
class __bucket_list_deallocator{
typedef _Alloc allocator_type;
typedef allocator_traits<allocator_type> __alloc_traits;
typedef typename __alloc_traits::size_type size_type;
__compressed_pair<size_type, allocator_type> __data_;
};
11.1.2 插入元素
__node_insert_unique
插入节点时先调用哈希函数计算当前节点值的哈希值,然后调用__node_insert_unique_prepare在哈希表中查找是否有对应的节点。没有的话再根据hash值插入节点。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
pair<typename __hash_table<_Tp, _Hash, _Equal, _Alloc>::iterator, bool>
__hash_table<_Tp, _Hash, _Equal, _Alloc>::__node_insert_unique(__node_pointer __nd){
__nd->__hash_ = hash_function()(__nd->__value_);
__next_pointer __existing_node =
__node_insert_unique_prepare(__nd->__hash(), __nd->__value_);
// Insert the node, unless it already exists in the container.
bool __inserted = false;
if (__existing_node == nullptr)
{
__node_insert_unique_perform(__nd);
__existing_node = __nd->__ptr();
__inserted = true;
}
return pair<iterator, bool>(iterator(__existing_node, this), __inserted);
}
__node_insert_unique_prepare
__node_insert_unique_prepare的基本流程是先利用__constrain_hash计算对应元素在哈希表中的节点。
__constrain_hash计算的方式比较简单就是,如果__bc比较大等于size_t::max就会按照__bc```对__hash```进行截断,否则就是根据二者大小选择是否取余。
size_t __constrain_hash(size_t __h, size_t __bc){
return !(__bc & (__bc - 1)) ? __h & (__bc - 1) :
(__h < __bc ? __h : __h % __bc);
}
拿到头结点后就是遍历每个链表寻找是否有对应的元素。最后根据当前哈希表的元素数量和实际大小选择是否进行rehash。如果进行rehash,rehash后的大小是当前bucket大小的2倍和元素数量/factor的最大值。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
_LIBCPP_INLINE_VISIBILITY
typename __hash_table<_Tp, _Hash, _Equal, _Alloc>::__next_pointer
__hash_table<_Tp, _Hash, _Equal, _Alloc>::__node_insert_unique_prepare(
size_t __hash, value_type& __value){
size_type __bc = bucket_count();
if (__bc != 0){
size_t __chash = std::__constrain_hash(__hash, __bc);
__next_pointer __ndptr = __bucket_list_[__chash];
if (__ndptr != nullptr){
for (__ndptr = __ndptr->__next_; __ndptr != nullptr &&
std::__constrain_hash(__ndptr->__hash(), __bc) == __chash;
__ndptr = __ndptr->__next_){
if (key_eq()(__ndptr->__upcast()->__value_, __value))
return __ndptr;
}
}
}
if (size()+1 > __bc * max_load_factor() || __bc == 0)
{
__rehash_unique(_VSTD::max<size_type>(2 * __bc + !std::__is_hash_power2(__bc),
size_type(std::ceil(float(size() + 1) / max_load_factor()))));
}
return nullptr;
}
__rehash
在进行rehash前还会再次计算实际需要的大小,最后调用__do_rehash做实际上的rehash,__do_rehash只会重新分配__bucket_list然后将之前元素的节点连接到__buck_list上。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
template <bool _UniqueKeys>
void
__hash_table<_Tp, _Hash, _Equal, _Alloc>::__rehash(size_type __n)
_LIBCPP_DISABLE_UBSAN_UNSIGNED_INTEGER_CHECK{
if (__n == 1)
__n = 2;
else if (__n & (__n - 1))
__n = std::__next_prime(__n);
size_type __bc = bucket_count();
if (__n > __bc)
__do_rehash<_UniqueKeys>(__n);
else if (__n < __bc){
__n = _VSTD::max<size_type>
(
__n,
std::__is_hash_power2(__bc) ? std::__next_hash_pow2(size_t(std::ceil(float(size()) / max_load_factor()))) :
std::__next_prime(size_t(std::ceil(float(size()) / max_load_factor())))
);
if (__n < __bc)
__do_rehash<_UniqueKeys>(__n);
}
}
从__node_insert_unique_perform的实现中能够看出这里采取的是头插入。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
_LIBCPP_INLINE_VISIBILITY
void __hash_table<_Tp, _Hash, _Equal, _Alloc>::__node_insert_unique_perform(
__node_pointer __nd) _NOEXCEPT{
size_type __bc = bucket_count();
size_t __chash = std::__constrain_hash(__nd->__hash(), __bc);
// insert_after __bucket_list_[__chash], or __first_node if bucket is null
__next_pointer __pn = __bucket_list_[__chash];
if (__pn == nullptr){
__pn =__p1_.first().__ptr();
__nd->__next_ = __pn->__next_;
__pn->__next_ = __nd->__ptr();
// fix up __bucket_list_
__bucket_list_[__chash] = __pn;
if (__nd->__next_ != nullptr)
__bucket_list_[std::__constrain_hash(__nd->__next_->__hash(), __bc)] = __nd->__ptr();
}else{
__nd->__next_ = __pn->__next_;
__pn->__next_ = __nd->__ptr();
}
++size();
}
11.1.3 删除元素
删除元素比较简单就是改变链表的指向,不会改变哈希表的大体结构。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
typename __hash_table<_Tp, _Hash, _Equal, _Alloc>::__node_holder
__hash_table<_Tp, _Hash, _Equal, _Alloc>::remove(const_iterator __p) _NOEXCEPT{
// current node
__next_pointer __cn = __p.__node_;
size_type __bc = bucket_count();
size_t __chash = std::__constrain_hash(__cn->__hash(), __bc);
// find previous node
__next_pointer __pn = __bucket_list_[__chash];
for (; __pn->__next_ != __cn; __pn = __pn->__next_)
;
// Fix up __bucket_list_
// if __pn is not in same bucket (before begin is not in same bucket) &&
// if __cn->__next_ is not in same bucket (nullptr is not in same bucket)
if (__pn == __p1_.first().__ptr()
|| std::__constrain_hash(__pn->__hash(), __bc) != __chash)
{
if (__cn->__next_ == nullptr
|| std::__constrain_hash(__cn->__next_->__hash(), __bc) != __chash)
__bucket_list_[__chash] = nullptr;
}
// if __cn->__next_ is not in same bucket (nullptr is in same bucket)
if (__cn->__next_ != nullptr)
{
size_t __nhash = std::__constrain_hash(__cn->__next_->__hash(), __bc);
if (__nhash != __chash)
__bucket_list_[__nhash] = __pn;
}
// remove __cn
__pn->__next_ = __cn->__next_;
__cn->__next_ = nullptr;
--size();
return __node_holder(__cn->__upcast(), _Dp(__node_alloc(), true));
}
clear
template <class _Tp, class _Hash, class _Equal, class _Alloc>
void __hash_table<_Tp, _Hash, _Equal, _Alloc>::clear() _NOEXCEPT{
if (size() > 0){
__deallocate_node(__p1_.first().__next_);
__p1_.first().__next_ = nullptr;
size_type __bc = bucket_count();
for (size_type __i = 0; __i < __bc; ++__i)
__bucket_list_[__i] = nullptr;
size() = 0;
}
}
template <class _Tp, class _Hash, class _Equal, class _Alloc>
void __hash_table<_Tp, _Hash, _Equal, _Alloc>::__deallocate_node(__next_pointer __np) _NOEXCEPT{
__node_allocator& __na = __node_alloc();
while (__np != nullptr){
__next_pointer __next = __np->__next_;
__node_pointer __real_np = __np->__upcast();
__node_traits::destroy(__na, _NodeTypes::__get_ptr(__real_np->__value_));
__node_traits::deallocate(__na, __real_np, 1);
__np = __next;
}
}
11.2 unordered_map
unordered_map中存储的元素是键值对。
template <class _Key, class _Tp, class _Hash = hash<_Key>, class _Pred = equal_to<_Key>,
class _Alloc = allocator<pair<const _Key, _Tp> > >
class _LIBCPP_TEMPLATE_VIS unordered_map
{
public:
// types
typedef _Key key_type;
typedef _Tp mapped_type;
typedef __type_identity_t<_Hash> hasher;
typedef __type_identity_t<_Pred> key_equal;
typedef __type_identity_t<_Alloc> allocator_type;
typedef pair<const key_type, mapped_type> value_type;
typedef value_type& reference;
typedef const value_type& const_reference;
static_assert((is_same<value_type, typename allocator_type::value_type>::value),
"Allocator::value_type must be same type as value_type");
private:
typedef __hash_value_type<key_type, mapped_type> __value_type;
typedef __unordered_map_hasher<key_type, __value_type, hasher, key_equal> __hasher;
typedef __unordered_map_equal<key_type, __value_type, key_equal, hasher> __key_equal;
typedef __rebind_alloc<allocator_traits<allocator_type>, __value_type> __allocator_type;
typedef __hash_table<__value_type, __hasher,
__key_equal, __allocator_type> __table;
__table __table_;
}
11.3 unordered_set
unordered_set中存储的元素是键值。
template <class _Value, class _Hash = hash<_Value>, class _Pred = equal_to<_Value>,
class _Alloc = allocator<_Value> >
class _LIBCPP_TEMPLATE_VIS unordered_set
{
public:
// types
typedef _Value key_type;
typedef key_type value_type;
typedef __type_identity_t<_Hash> hasher;
typedef __type_identity_t<_Pred> key_equal;
typedef __type_identity_t<_Alloc> allocator_type;
typedef value_type& reference;
typedef const value_type& const_reference;
static_assert((is_same<value_type, typename allocator_type::value_type>::value),
"Allocator::value_type must be same type as value_type");
static_assert(is_same<allocator_type, __rebind_alloc<allocator_traits<allocator_type>, value_type> >::value,
"[allocator.requirements] states that rebinding an allocator to the same type should result in the "
"original allocator");
private:
typedef __hash_table<value_type, hasher, key_equal, allocator_type> __table;
__table __table_;
}