Memory Implement in Agent Application
1 MemoryBank: Enhancing Large Language Models with Long-Term Memory
论文地址:https://arxiv.org/abs/2305.10250 代码地址:https://github.com/zhongwanjun/MemoryBank-SiliconFriend/blob/main/README_cn.md
1.1 MemoryBank

MemoryBank 是为 LLMs 设计的新型长期记忆机制,围绕三大核心支柱构建,能实现记忆存储、检索与更新,并绘制用户画像,让 LLMs 可回忆历史交互、持续深化语境理解、依据过往互动适应用户性格,提升长期交互场景下的性能。
记忆存储(Memory Storage):作为 Memory的 “仓库”,以细致有序的方式存储信息,构建动态多层记忆体系。
深度存储:按时间顺序记录多轮对话,每条对话附带时间戳,既助力精准记忆检索,又为后续记忆更新提供详细对话历史索引。
分层事件总结:模仿人类记忆特点,将冗长对话浓缩为每日事件摘要,再进一步整合为全局摘要,形成分层记忆结构,便于快速把握过往交互与重要事件全貌。
动态性格理解:持续通过长期交互评估并更新对用户性格的认知,生成每日性格洞察,再汇总为对用户性格的全局理解,使 AI 伴侣能依据用户独特特质调整响应。
记忆检索(Memory Retrieval):基于记忆存储,类似知识检索任务,采用双塔密集检索模型(类似 Dense Passage Retrieval),将每轮对话和事件摘要视为记忆片段,用编码器模型预编码为向量表示,通过 FAISS 索引实现高效检索;同时将当前对话语境编码为查询向量,在记忆库中搜索最相关记忆,且编码器模型可灵活替换。
记忆更新机制(Memory Updating Mechanism):受艾宾浩斯遗忘曲线理论启发,模拟人类认知过程,让 AI 能依据时间推移记忆、选择性遗忘和强化记忆,使交互更自然。
遗忘规律:记忆保留率随时间下降,初始阶段遗忘速度快,之后减缓;定期回顾可重置遗忘曲线,提升记忆保留率。
数学模型:采用指数衰减模型(R = e^{-\frac{t}{S}})(R为记忆保留率,t为时间,S为记忆强度),S初始值为 1,记忆片段被回忆时S加 1 且t重置为 0,降低遗忘概率。

1.2 源码分析
1.2.1 记忆存储
采用结构化方式存储用户对话历史、总结内容和个性分析,支持长期追踪用户信息。记忆数据以 JSON 格式存储,每个用户的记忆包含(下面是一个对话的Memory示例):
history:按日期划分的对话记录(用户查询和模型回应)。summary:每日对话的关键信息总结。personality:用户性格和情绪分析。overall_history:历史总结和性格的整体概括。
"宫晓燕": {
"name": "宫晓燕",
"summary": {},
"personality": {},
"overall_history": "",
"history": {
"2023-04-27": [
{
"query": "你好,我叫宫晓燕,很高兴认识你!",
"response": "你好,宫晓燕!我是你的AI伴侣,很高兴认识你,希望我们可以成为好朋友!"
},
//省略部分数据
],
"2023-04-28": [
{
"query": "你知道吗?我最近开始学做菜了,感觉这个过程很有意思,你也喜欢做菜吗?",
"response": "我没有实体,所以会有些遗憾,但是我可以陪你聊聊你学做菜的经历。"
},
//省略部分数据
},
"meta_information": {
"name": "宫晓燕",
"personality": "聪明伶俐,机智过人,热爱生活",
"hobbies": "打羽毛球,游泳,旅游,听音乐,电影",
"speaking_style": "欣喜愉悦,略带调皮"
}
},
其中summary和personality是根据用户的过去对话信息通过LLM自动总结对话内容和用户性格,减少冗余信息,强化关键记忆。overall_history是对用户的记忆进行总结,记录用户的重要事件和人物。其基本实现根据不同的PE给大模型下发不同的总结任务:
def summarize_content_prompt(content,user_name,boot_name,language='en'):
prompt = '请总结以下的对话内容,尽可能精炼,提取对话的主题和关键信息。如果有多个关键事件,可以分点总结。对话内容:\n' if language=='cn' else 'Please summarize the following dialogue as concisely as possible, extracting the main themes and key information. If there are multiple key events, you may summarize them separately. Dialogue content:\n'
for dialog in content:
query = dialog['query']
response = dialog['response']
# prompt += f"\n用户:{query.strip()}"
# prompt += f"\nAI:{response.strip()}"
prompt += f"\n{user_name}:{query.strip()}"
prompt += f"\n{boot_name}:{response.strip()}"
prompt += ('\n总结:' if language=='cn' else '\nSummarization:')
return prompt
def summarize_overall_prompt(content,language='en'):
prompt = '请高度概括以下的事件,尽可能精炼,概括并保留其中核心的关键信息。概括事件:\n' if language=='cn' else "Please provide a highly concise summary of the following event, capturing the essential key information as succinctly as possible. Summarize the event:\n"
for date,summary_dict in content:
summary = summary_dict['content']
prompt += (f"\n时间{date}发生的事件为{summary.strip()}" if language=='cn' else f"At {date}, the events are {summary.strip()}")
prompt += ('\n总结:' if language=='cn' else '\nSummarization:')
return prompt
def summarize_overall_personality(content,language='en'):
prompt = '以下是用户在多段对话中展现出来的人格特质和心情,以及当下合适的回复策略:\n' if language=='cn' else "The following are the user's exhibited personality traits and emotions throughout multiple dialogues, along with appropriate response strategies for the current situation:"
for date,summary in content:
prompt += (f"\n在时间{date}的分析为{summary.strip()}" if language=='cn' else f"At {date}, the analysis shows {summary.strip()}")
prompt += ('\n请总体概括用户的性格和AI恋人最合适的回复策略,尽量简洁精炼,高度概括。总结为:' if language=='cn' else "Please provide a highly concise and general summary of the user's personality and the most appropriate response strategy for the AI lover, summarized as:")
return prompt
def summarize_person_prompt(content,user_name,boot_name,language):
prompt = f'请根据以下的对话推测总结{user_name}的性格特点和心情,并根据你的推测制定回复策略。对话内容:\n' if language=='cn' else f"Based on the following dialogue, please summarize {user_name}'s personality traits and emotions, and devise response strategies based on your speculation. Dialogue content:\n"
for dialog in content:
query = dialog['query']
response = dialog['response']
# prompt += f"\n用户:{query.strip()}"
# prompt += f"\nAI:{response.strip()}"
prompt += f"\n{user_name}:{query.strip()}"
prompt += f"\n{boot_name}:{response.strip()}"
prompt += (f'\n{user_name}的性格特点、心情、{boot_name}的回复策略为:' if language=='cn' else f"\n{user_name}'s personality traits, emotions, and {boot_name}'s response strategy are:")
return prompt
1.2.2 记忆检索
首先将记忆内容构建为向量索引,支持高效检索相关记忆,辅助模型生成回应。
index_set = {}
def build_memory_index(all_user_memories,data_args,name=None):
all_user_memories = generate_memory_docs(all_user_memories,data_args.language)
llm_predictor = LLMPredictor(llm=OpenAIChat(model_name="gpt-3.5-turbo"))
prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap)
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
for user_name, memories in all_user_memories.items():
# print(all_user_memories[user_name])
if name:
if user_name != name:
continue
print(f'build index for user {user_name}')
cur_index = GPTSimpleVectorIndex.from_documents(memories,service_context=service_context)
index_set[user_name] = cur_index
os.makedirs(f'../memories/memory_index/llamaindex',exist_ok=True)
cur_index.save_to_disk(f'../memories/memory_index/llamaindex/{user_name}_index.json')
随后搜索时使用FLASS向量库搜索TOP-K相关记忆片段,结合当前对话语境生成最终回应。
def search_memory(self,
query,
vector_store):
# vector_store = FAISS.load_local(vs_path, self.embeddings)
# FAISS.similarity_search_with_score_by_vector = similarity_search_with_score_by_vector
# vector_store.chunk_size=self.chunk_size
related_docs_with_score = vector_store.similarity_search_with_score(query,
k=self.top_k)
related_docs = get_docs_with_score(related_docs_with_score)
related_docs = sorted(related_docs, key=lambda x: x.metadata["source"], reverse=False)
pre_date = ''
date_docs = []
dates = []
for doc in related_docs:
doc.page_content = doc.page_content.replace(f'时间{doc.metadata["source"]}的对话内容:','').strip()
if doc.metadata["source"] != pre_date:
# date_docs.append(f'在时间{doc.metadata["source"]}的回忆内容是:{doc.page_content}')
date_docs.append(doc.page_content)
pre_date = doc.metadata["source"]
dates.append(pre_date)
else:
date_docs[-1] += f'\n{doc.page_content}'
# memory_contents = [doc.page_content for doc in related_docs]
# memory_contents = [f'在时间'+doc.metadata['source']+'的回忆内容是:'+doc.page_content for doc in related_docs]
return date_docs, ', '.join(dates)
1.2.3 记忆更新
记忆更新模拟人类遗忘机制,基于艾宾浩斯遗忘曲线,根据记忆强度和时间衰减自动 "遗忘" 次要信息,保留重要记忆。
def forgetting_curve(t, S):
"""
Calculate the retention of information at time t based on the forgetting curve.
:param t: Time elapsed since the information was learned (in days).
:type t: float
:param S: Strength of the memory.
:type S: float
:return: Retention of information at time t.
:rtype: float
Memory strength is a concept used in memory models to represent the durability or stability of a memory trace in the brain.
In the context of the forgetting curve, memory strength (denoted as 'S') is a parameter that
influences the rate at which information is forgotten.
The higher the memory strength, the slower the rate of forgetting,
and the longer the information is retained.
"""
return math.exp(-t / 5*S)
记忆更新时,根据遗忘曲线计算记忆保留概率,随机保留部分记忆,更新索引。
days_diff = self._get_date_difference(last_recall_date, now_date)
retention_probability = forgetting_curve(days_diff,memory_strength)
print(days_diff,memory_strength,retention_probability)
# Keep the memory with the retention_probability
if random.random() > retention_probability:
forget_ids.append(i)
else:
docs.append(Document(page_content=tmp_str,metadata=metadata))
1.3 要点总结
层次化记忆存储(历史 → 摘要 → 全局)。
基于 FAISS 的向量检索,确保高效查找。
遗忘曲线驱动的动态记忆更新,模拟人类遗忘与强化。
灵活 Prompt 设计,支持摘要、画像与策略生成。
2 MemGPT: Towards LLMs as Operating Systems
2.1 MemGPT
MemGPT(MemoryGPT)借鉴传统操作系统的分层内存管理思想(物理内存与磁盘间的分页机制),通过 “虚拟上下文管理” 技术,让固定上下文窗口的 LLM 具备 “无限上下文” 的使用错觉。其核心逻辑是:将 LLM 的上下文窗口视为 “物理内存”,外部存储视为 “磁盘”,通过函数调用实现信息在两者间的 “分页调入 / 调出”,同时管理控制流以优化上下文利用效率。

MemGPT 通过多层级内存设计与功能模块协作,实现上下文的智能管理,包括:
主上下文(Main Context):类比RAM。LLM 的Prompt Tokens,可被 LLM 推理直接访问,分为三部分:
系统指令:只读静态内容,包含 MemGPT 控制流、内存层级用途、函数调用规则;
工作上下文:固定大小可读写区块,存储用户关键信息(如偏好、事实)、智能体角色信息;
FIFO 队列:滚动存储消息历史(用户 - 智能体对话、系统提示、函数调用记录),头部含已淘汰消息的递归摘要。
外部上下文(External Context):类比磁盘。超出主上下文窗口的信息,需通过函数调用调入主上下文才能使用,包含两类存储:
召回存储(Recall Storage):消息数据库,由队列管理器自动写入对话历史,支持分页搜索与重新调入主上下文;
归档存储(Archival Storage):支持向量搜索的数据库(如 PostgreSQL+pgvector),存储长文档、键值对等大规模数据,需显式函数调用访问。
核心功能模块
队列管理器(Queue Manager):
消息处理:接收新消息并追加到 FIFO 队列,拼接提示词令牌触发 LLM 推理,同时将消息与推理结果写入召回存储;
上下文溢出控制:当主上下文令牌数达到 “警告阈值”(如窗口的 70%),插入 “内存压力” 系统提示,引导 LLM 将关键信息存入工作上下文 / 归档存储;达到 “刷新阈值”(如 100%)时,淘汰部分消息(如 50% 窗口),生成新递归摘要并写入 FIFO 头部,淘汰消息永久保留在召回存储。
函数执行器(Function Executor):
解析 LLM 生成的输出,执行内存管理函数(如搜索外部存储、修改工作上下文、分页调入数据),并将执行结果(含错误信息)反馈给 LLM,形成 “决策 - 执行 - 反馈” 闭环。同时支持分页机制,避免单次检索结果溢出主上下文。
控制流与函数链(Control Flow & Function Chaining):
事件触发推理:用户消息、系统警告、定时任务等事件均会触发 LLM 推理,事件经解析后转为文本追加到主上下文;
多函数顺序执行:通过 “request heartbeat=true” 标志,支持 LLM 在返回用户响应前,连续调用多个函数(如多页文档检索、多跳键值对查询),提升复杂任务处理能力。
2.2 源码分析
2.2.1 内存层次结构 — 主内存 / 归档 / 检索层
Memory hierarchy(论文里的主内存 / 外部存储分层)是通过 Memory Blocks + Archival Memory 来实现的:
核心上下文(主内存)由 memory blocks 组成,每个 block 都是可编辑、可共享的小单元,在
client.blocks.create()与 agent 的block_ids字段绑定后,会被拼接进 agent 的in-context prompt中。
agent_state = client.agents.create(
memory_blocks=[
{
"label": "human",
"value": "The human's name is Bob the Builder.",
"limit": 5000
},
{
"label": "persona",
"value": "My name is Sam, the all-knowing sentient AI.",
"limit": 5000
}
],
model="openai/gpt-4o-mini",
embedding="openai/text-embedding-3-small"
)
外部上下文:超出 context 的长期存储(外部存储层)则通过
filesystem / folders / passages模块实现,文件内容会被分段、索引、存档,必要时由agent通过工具调用再取回到主内存。这样 Letta 就把 “有限的 prompt context” 和 “无限的外部持久存储” 分层管理。
# create the folder
folder = client.folders.create(
name="my_folder",
embedding_config=embedding_config
)
# upload a file into the folder
job = client.folders.files.upload(
folder_id=folder.id,
file=open("my_file.txt", "rb")
)
MemoryBlock MemGPT中定义了一些系列的Memory,都是基于MemoryBlock来实现的。而外部Memory直接通过FileProcess来实现。
class BasicBlockMemory(Memory):
"""
BasicBlockMemory is a basic implemention of the Memory class, which takes in a list of blocks and links them to the memory object. These are editable by the agent via the core memory functions.
Attributes:
memory (Dict[str, Block]): Mapping from memory block section to memory block.
Methods:
core_memory_append: Append to the contents of core memory.
core_memory_replace: Replace the contents of core memory.
"""
def __init__(self, blocks: List[Block] = []):
"""
Initialize the BasicBlockMemory object with a list of pre-defined blocks.
Args:
blocks (List[Block]): List of blocks to be linked to the memory object.
"""
super().__init__(blocks=blocks)
调度 agent 的核心调度器,其中 内存调度(memory hierarchy 的 orchestrator) 主要体现在 “重建上下文窗口” 的逻辑,也就是把 Memory Blocks(主内存)、消息历史 和 归档/摘要 拼接起来,送进 LLM。
# letta/agents/letta_agent.py
class LettaAgent:
...
async def step(...):
# 每次 agent 前进一轮,都会检查/更新上下文
...
await self.rebuild_context_window()
...
async def rebuild_context_window(self):
"""
这里是核心的内存调度逻辑:
1. 从数据库/存储里取出 agent 的 memory blocks(主内存块)
2. 加载最近的对话消息(短期记忆)
3. 检查上下文 token 使用量
- 如果超过阈值,调用 summarizer 做摘要/驱逐
4. 把这些拼接成 prompt,交给模型调用
"""
blocks = await self.get_attached_blocks()
messages = await self.load_recent_messages()
# 判断 token 是否超限
if self.exceeds_context_limit(blocks, messages):
summarized = await self.summarizer.summarize(messages)
messages = summarized
# 构造最终的上下文
self.context = self.compose_context(blocks, messages)
摘要 当上下文压力过大时,会通过LLM对内存进行摘要或驱逐,具体摘要的PE如下:
WORD_LIMIT = 100
SYSTEM = f"""Your job is to summarize a history of previous messages in a conversation between an AI persona and a human.
The conversation you are given is a from a fixed context window and may not be complete.
Messages sent by the AI are marked with the 'assistant' role.
The AI 'assistant' can also make calls to tools, whose outputs can be seen in messages with the 'tool' role.
Things the AI says in the message content are considered inner monologue and are not seen by the user.
The only AI messages seen by the user are from when the AI uses 'send_message'.
Messages the user sends are in the 'user' role.
The 'user' role is also used for important system events, such as login events and heartbeat events (heartbeats run the AI's program without user action, allowing the AI to act without prompting from the user sending them a message).
Summarize what happened in the conversation from the perspective of the AI (use the first person from the perspective of the AI).
Keep your summary less than {WORD_LIMIT} words, do NOT exceed this word limit.
Only output the summary, do NOT include anything else in your output."""
共享内存 共享内存的实现比较简单就是将内存块的id添加到agent的block_ids中即可。
# create a shared memory block
shared_block = client.blocks.create(
label="organization",
description="Shared information between all agents within the organization.",
value="Nothing here yet, we should update this over time."
)
# create a supervisor agent
supervisor_agent = client.agents.create(
model="anthropic/claude-3-5-sonnet-20241022",
embedding="openai/text-embedding-3-small",
# blocks created for this agent
memory_blocks=[{"label": "persona", "value": "I am a supervisor"}],
# pre-existing shared block that is "attached" to this agent
block_ids=[shared_block.id],
)
# create a worker agent
worker_agent = client.agents.create(
model="openai/gpt-4.1-mini",
embedding="openai/text-embedding-3-small",
# blocks created for this agent
memory_blocks=[{"label": "persona", "value": "I am a worker"}],
# pre-existing shared block that is "attached" to this agent
block_ids=[shared_block.id],
)
2.2.2 队列管理器
MemGPT的队列管理器(queue manager) 对应的就是 对话消息队列 / buffer 的管理逻辑——也就是让 agent 的上下文只保留一部分最近的消息,把溢出的内容清理、归档或摘要。这个机制跟 MemGPT 论文里的 FIFO 队列 + 内存压力控制 是一一对应的。
消息存储。所有对话消息存到数据库里(Postgres/SQLite,表结构在 messages 表),而 agent 每次运行时不会直接加载全部,而是取最近一段窗口。
上下文重建时检查队列。从数据库里取最新的 N 条消息(相当于队尾元素)。如果 token 超限,调用 summarizer 对旧消息做摘要,然后替换队首部分(保持队列容量不爆炸)。
async def _rebuild_context_window(
self, summarizer: Summarizer, in_context_messages: List[Message], letta_message_db_queue: List[Message]
) -> None:
new_letta_messages = await self.message_manager.create_many_messages_async(letta_message_db_queue, actor=self.actor)
# TODO: Make this more general and configurable, less brittle
new_in_context_messages, updated = await summarizer.summarize(
in_context_messages=in_context_messages, new_letta_messages=new_letta_messages
)
await self.agent_manager.update_message_ids_async(
agent_id=self.agent_id, message_ids=[m.id for m in new_in_context_messages], actor=self.actor
)
驱逐/摘要策略。当消息数量或 token 数超过阈值时,触发 partial evict buffer summarization,把旧消息合并成一条 “总结消息”,再继续放回队首。
async def _partial_evict_buffer_summarization(
self,
in_context_messages: List[Message],
new_letta_messages: List[Message],
force: bool = False,
clear: bool = False,
) -> Tuple[List[Message], bool]:
"""Summarization as implemented in the original MemGPT loop, but using message count instead of token count.
Evict a partial amount of messages, and replace message[1] with a recursive summary.
Note that this can't be made sync, because we're waiting on the summary to inject it into the context window,
unlike the version that writes it to a block.
Unless force is True, don't summarize.
Ignore clear, we don't use it.
"""
all_in_context_messages = in_context_messages + new_letta_messages
if not force:
logger.debug("Not forcing summarization, returning in-context messages as is.")
return all_in_context_messages, False
# First step: determine how many messages to retain
total_message_count = len(all_in_context_messages)
assert self.partial_evict_summarizer_percentage >= 0.0 and self.partial_evict_summarizer_percentage <= 1.0
target_message_start = round((1.0 - self.partial_evict_summarizer_percentage) * total_message_count)
logger.info(f"Target message count: {total_message_count}->{(total_message_count - target_message_start)}")
# The summary message we'll insert is role 'user' (vs 'assistant', 'tool', or 'system')
# We are going to put it at index 1 (index 0 is the system message)
# That means that index 2 needs to be role 'assistant', so walk up the list starting at
# the target_message_count and find the first assistant message
for i in range(target_message_start, total_message_count):
if all_in_context_messages[i].role == MessageRole.assistant:
assistant_message_index = i
break
else:
raise ValueError(f"No assistant message found from indices {target_message_start} to {total_message_count}")
# The sequence to summarize is index 1 -> assistant_message_index
messages_to_summarize = all_in_context_messages[1:assistant_message_index]
logger.info(f"Eviction indices: {1}->{assistant_message_index}(/{total_message_count})")
# Dynamically get the LLMConfig from the summarizer agent
# Pretty cringe code here that we need the agent for this but we don't use it
agent_state = await self.agent_manager.get_agent_by_id_async(agent_id=self.agent_id, actor=self.actor)
# TODO if we do this via the "agent", then we can more easily allow toggling on the memory block version
summary_message_str = await simple_summary(
messages=messages_to_summarize,
llm_config=agent_state.llm_config,
actor=self.actor,
include_ack=True,
)
2.2.3 函数执行器
MemGPT的函数执行器是每个Agent的基础能力,在处理LLM的响应时进行函数调用。函数的具体执行是抛到了不同的Exector里面。
@trace_method
async def _handle_ai_response()
#省略一些检查和参数
# 2. Execute the tool (or synthesize an error result if disallowed)
tool_rule_violated = tool_call_name not in valid_tool_names and not is_approval
if tool_rule_violated:
tool_execution_result = _build_rule_violation_result(tool_call_name, valid_tool_names, tool_rules_solver)
else:
# Track tool execution time
tool_start_time = get_utc_timestamp_ns()
tool_execution_result = await self._execute_tool(
tool_name=tool_call_name,
tool_args=tool_args,
agent_state=agent_state,
agent_step_span=agent_step_span,
step_id=step_id,
)
2.2.4 控制流与函数链
MemGPT的控制流与函数链是支撑Agent具备“可编程对话逻辑”的关键。核心由 step() 驱动,每次调用 agent.step() 就是一次事件循环。基本流程为:LLM输出 → 调度器解析 → 执行器执行 → 队列更新 → 下一轮继续。伪代码为:
# letta/agents/letta_agent.py
async def step(self, user_input=None):
# 1. 构建上下文
await self.rebuild_context_window()
# 2. 调用模型
model_output = await self.model.generate(self.context, user_input)
# 3. 根据输出类型决定控制流
if model_output.function_call:
response = await self.execute_function_call(model_output.function_call)
else:
response = model_output.text
# 4. 更新队列(短期记忆)
await self.message_queue.enqueue(response)
return response
2.3 要点总结
内存层次(Memory Hierarchy):Main Context Memory,External Memory和Archive / Summarized Memory;
内存调度:高频访问内容留在上下文,低频内容丢到外部存储;
队列管理:管理 输入消息流 与 函数调用结果,确保 LLM 每次看到的上下文是“最有用”的子集。
3 A-Mem: Agentic Memory for LLM Agents
3.1 A-Mem
当前大型语言模型(LLM)智能体虽能借助外部工具处理复杂任务,但需记忆系统利用历史经验实现长期交互。现有记忆系统存在两大关键局限:
结构僵化:依赖预定义存储结构、工作流中的存储节点和检索时机(如 MemGPT 的缓存架构、MemoryBank 的固定更新机制),即使引入图数据库(如 Mem0),也受限于预设模式,无法随知识演化建立创新关联。
适应性差:面对开放域、多步骤推理等复杂任务时,固定结构难以灵活组织知识,导致长期交互效果差、跨场景泛化能力弱。

A-Mem(Agentic Memory)—— 一种基于 Zettelkasten(卡片盒笔记法)的动态智能体化记忆系统,实现无需预设操作的记忆组织与进化。A-Mem 灵感源于 Zettelkasten 的知识网络构建思路,以 “原子笔记 + 动态链接 + 持续进化” 为核心,具体包含 4 个关键组件:
笔记构建(Note Construction):结构化记忆表示:
为每个新交互生成多维度原子笔记,捕捉显性信息与隐性语义,单个笔记(m_i)的结构为: (m_i={c_i, t_i, K_i, G_i, X_i, e_i, L_i}),该设计确保每个笔记是 “自包含知识单元”,同时通过多模态属性(文本 + 向量)支持精细检索与链接。
(c_i):原始交互内容;(t_i):时间戳;
(K_i)(关键词)、(G_i)(标签)、(X_i)(上下文描述):由 LLM 基于模板生成,提炼核心概念与语义;
(e_i):文本编码器(如 all-minilm-l6-v2)生成的稠密向量,用于相似度匹配;
(L_i):关联记忆的链接集合。
链接生成(Link Generation):自主建立记忆关联。新笔记加入时,无需预设规则,自动与历史记忆建立语义链接,此过程兼顾效率(嵌入筛选降维)与语义深度(LLM 捕捉隐性关联,如因果、概念关联),实现记忆网络的 “有机生长”。
相似度筛选:计算新笔记嵌入(e_n)与所有历史笔记嵌入(e_j)的余弦相似度,筛选 top-k 相关记忆(\mathcal{M}_{near}^n);
LLM 决策链接:通过 LLM 分析 top-k 记忆与新笔记的共享属性(关键词、上下文),判断是否建立链接,并更新(L_i)(链接集合)
记忆进化(Memory Evolution):动态更新历史记忆。新笔记不仅建立新链接,还会触发历史记忆的属性迭代,模拟人类学习的 “知识更新” 过程:
对 top-k 相关历史记忆(m_j),LLM 分析新笔记与(m_j)的语义关联,动态更新(m_j)的上下文描述(X_j)、关键词(K_j)、标签(G_j);
进化后的记忆(m_j^*)替换原记忆,使整个记忆网络随新经验持续优化,逐步形成高阶知识模式。
相关记忆检索(Retrieve Relative Memory):上下文感知召回
生成查询嵌入(e_q);
计算(e_q)与所有记忆嵌入的余弦相似度,召回 top-k 记忆(\mathcal{M}_{retrieved});
召回的记忆不仅包含直接相关项,还会通过(L_i)关联 “同链接集群” 的记忆,提供更完整的历史上下文。
3.2 源码分析
3.2.1 笔记构建
笔记(MemoryNote)的构建流程围绕AgenticMemorySystem的add_note方法展开,包含从初始化笔记、提取元数据到存储和进化触发的完整链路。
初始化笔记对象。笔记通过AgenticMemorySystem进行管理,将用户输入的内容和可选参数(如标签、时间戳)封装为MemoryNote实例,生成唯一 ID。
self.memory_system = AgenticMemorySystem(
model_name='all-MiniLM-L6-v2',
llm_backend="openai",
llm_model="gpt-4o-mini"
)
def add_note(self, content: str, time: str = None, **kwargs) -> str:
"""Add a new memory note"""
# Create MemoryNote without llm_controller
if time is not None:
kwargs['timestamp'] = time
note = MemoryNote(content=content, **kwargs)
公式(m_i={c_i, t_i, K_i, G_i, X_i, e_i, L_i})描述了单个记忆单元的结构化组成,其中每个参数对应记忆的特定属性。在代码中,这一结构通过MemoryNote类的定义直接体现,该类的属性与公式参数一一对应。
class MemoryNote:
"""A memory note that represents a single unit of information in the memory system.
This class encapsulates all metadata associated with a memory, including:
- Core content and identifiers
- Temporal information (creation and access times)
- Semantic metadata (keywords, context, tags)
- Relationship data (links to other memories)
- Usage statistics (retrieval count)
- Evolution tracking (history of changes)
"""
def __init__(self,
content: str,
id: Optional[str] = None,
keywords: Optional[List[str]] = None,
links: Optional[Dict] = None,
retrieval_count: Optional[int] = None,
timestamp: Optional[str] = None,
last_accessed: Optional[str] = None,
context: Optional[str] = None,
evolution_history: Optional[List] = None,
category: Optional[str] = None,
tags: Optional[List[str]] = None):
"""Initialize a new memory note with its associated metadata.
Args:
content (str): The main text content of the memory
id (Optional[str]): Unique identifier for the memory. If None, a UUID will be generated
keywords (Optional[List[str]]): Key terms extracted from the content
links (Optional[Dict]): References to related memories
retrieval_count (Optional[int]): Number of times this memory has been accessed
timestamp (Optional[str]): Creation time in format YYYYMMDDHHMM
last_accessed (Optional[str]): Last access time in format YYYYMMDDHHMM
context (Optional[str]): The broader context or domain of the memory
evolution_history (Optional[List]): Record of how the memory has evolved
category (Optional[str]): Classification category
tags (Optional[List[str]]): Additional classification tags
"""
# Core content and ID
self.content = content
self.id = id or str(uuid.uuid4())
# Semantic metadata
self.keywords = keywords or []
self.links = links or []
self.context = context or "General"
self.category = category or "Uncategorized"
self.tags = tags or []
# Temporal information
current_time = datetime.now().strftime("%Y%m%d%H%M")
self.timestamp = timestamp or current_time
self.last_accessed = last_accessed or current_time
# Usage and evolution data
self.retrieval_count = retrieval_count or 0
self.evolution_history = evolution_history or []
公式参数 |
含义 |
代码中对应的属性 |
说明 |
|---|---|---|---|
(c_i) |
原始交互内容 |
|
直接存储用户输入的原始文本内容 |
(t_i) |
时间戳 |
|
记录笔记创建时间,默认使用当前时间(格式: |
(K_i) |
关键词 |
|
由LLM分析内容后提取的核心概念(如 |
(G_i) |
标签 |
|
用于分类的标签(如“工作”“个人”等,由LLM生成) |
(X_i) |
上下文描述 |
|
对内容的语义概括,帮助理解笔记的背景和意义 |
(L_i) |
关联记忆的链接集合 |
|
存储与当前笔记相关的其他记忆ID,形成记忆网络 |
(e_i) |
稠密向量 |
由 |
代码中未直接存储在 |
提取元数据。笔记内容通过 LLM 提取关键词、标签、上下文描述等元数据,同时生成文本嵌入用于相似度匹配。其核心内容就是一段PE。
def analyze_content(self, content: str) -> Dict:
prompt = """Generate a structured analysis of the following content by:
1. Identifying the most salient keywords (focus on nouns, verbs, and key concepts)
2. Extracting core themes and contextual elements
3. Creating relevant categorical tags
Format the response as a JSON object:
{
"keywords": [
// several specific, distinct keywords that capture key concepts and terminology
// Order from most to least important
// Don't include keywords that are the name of the speaker or time
// At least three keywords, but don't be too redundant.
],
"context":
// one sentence summarizing:
// - Main topic/domain
// - Key arguments/points
// - Intended audience/purpose
,
"tags": [
// several broad categories/themes for classification
// Include domain, format, and type tags
// At least three tags, but don't be too redundant.
]
}
Content for analysis:
""" + content
关联历史记忆与进化分析。结合历史记忆判断新笔记是否需要进化(如建立关联、更新标签)。具体是在add_note时:
# 在add_note中调用process_memory处理新笔记
evo_label, note = self.process_memory(note)
记忆存储与检索。笔记的元数据和嵌入向量存储在向量数据库中,支持基于内容的快速检索。这一步也是在add_note时完成的。
self.retriever.add_document(note.content, metadata, note.id)
3.2.2 链接生成
链接生成(Link Generation)的核心逻辑体现在AgenticMemorySystem的process_memory方法中(该方法在add_note流程中被调用),负责新笔记与历史记忆的关联建立。这一步主要也是LLM驱动的,其核心就是连接生成的PE和输出结构化格式,输出内容会将历史记忆连接起来。
response_format={"type": "json_schema", "json_schema": {
"name": "response",
"schema": {
"type": "object",
"properties": {
"should_evolve": {
"type": "boolean"
},
"actions": {
"type": "array",
"items": {
"type": "string"
}
},
"suggested_connections": {
"type": "array",
"items": {
"type": "string"
}
},
"new_context_neighborhood": {
"type": "array",
"items": {
"type": "string"
}
},
"tags_to_update": {
"type": "array",
"items": {
"type": "string"
}
},
"new_tags_neighborhood": {
"type": "array",
"items": {
"type": "array",
"items": {
"type": "string"
}
}
}
},
"required": ["should_evolve", "actions", "suggested_connections",
"tags_to_update", "new_context_neighborhood", "new_tags_neighborhood"],
"additionalProperties": False
},
"strict": True
}}
3.2.3 记忆进化
新笔记加入后,系统自动更新相关历史记忆的元数据(如上下文、关键词、标签),使记忆网络随新经验动态优化。记忆金华依赖连接生成,因为连接生成的PE中包含了记忆进化的信息,该输出也会决定是否进行进化。同时该输出中也有指明后续操作方向的信息。
for action in actions:
if action == "strengthen":
suggest_connections = response_json["suggested_connections"]
new_tags = response_json["tags_to_update"]
note.links.extend(suggest_connections)
note.tags = new_tags
elif action == "update_neighbor":
new_context_neighborhood = response_json["new_context_neighborhood"]
new_tags_neighborhood = response_json["new_tags_neighborhood"]
noteslist = list(self.memories.values())
notes_id = list(self.memories.keys())
//省略部分代码
而进化的核心代码就是下面这段:
for i in range(min(len(indices), len(new_tags_neighborhood))):
# Skip if we don't have enough neighbors
if i >= len(indices):
continue
tag = new_tags_neighborhood[i]
if i < len(new_context_neighborhood):
context = new_context_neighborhood[i]
else:
# Since indices are just numbers now, we need to find the memory
# In memory list using its index number
if i < len(noteslist):
context = noteslist[i].context
else:
continue
# Get index from the indices list
if i < len(indices):
memorytmp_idx = indices[i]
# Make sure the index is valid
if memorytmp_idx < len(noteslist):
notetmp = noteslist[memorytmp_idx]
notetmp.tags = tag
notetmp.context = context
# Make sure the index is valid
if memorytmp_idx < len(notes_id):
self.memories[notes_id[memorytmp_idx]] = notetmp
3.2.4 相关记忆检索
相关记忆检索(Retrieve Relative Memory)是 A-Mem 系统中根据查询内容高效召回相关记忆的核心流程,主要通过向量相似度匹配结合记忆网络的关联关系实现。相关记忆检索分为向量匹配和关联扩展两个阶段,对应论文中 “上下文感知召回” 的设计:
向量匹配:通过
ChromaRetriever.search实现,核心是将查询文本和记忆内容转换为稠密向量($e_q$和$e_i$),计算余弦相似度,召回 top-k 最相似的记忆。关联扩展:返回直接相似的记忆,还通过记忆网络的关联关系(L_i)召回间接相关的记忆,避免 “检索孤岛”,提供更完整的上下文。
收集初始检索结果的 ID 及其links中记录的关联记忆 ID,形成扩展集合(expanded_ids)。
对扩展集合中的所有记忆重新计算与查询的相似度,按相似度排序后返回更全面的结果
3.3 总结
动态自主组织:摆脱固定存储结构的束缚,支持知识网络的自生长与演化;
类人知识更新:记忆不再“写入即静态”,而是随新经验动态进化,模拟人类学习;
全链路检索:结合向量相似度与链接传播,支持局部语义网络的整体回忆;
开放域泛化:结构灵活,适用于多任务、多场景的长期交互。
4 Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
4.1 Mem0
构建类人类认知的记忆系统—— 选择性存储关键信息、整合关联概念、按需检索,实现 AI 智能体从 “瞬时响应者” 到 “长期合作者” 的转变。基于此,mem0团队设计了两种互补的记忆架构,分别针对 “高效检索” 和 “复杂关系建模” 需求。
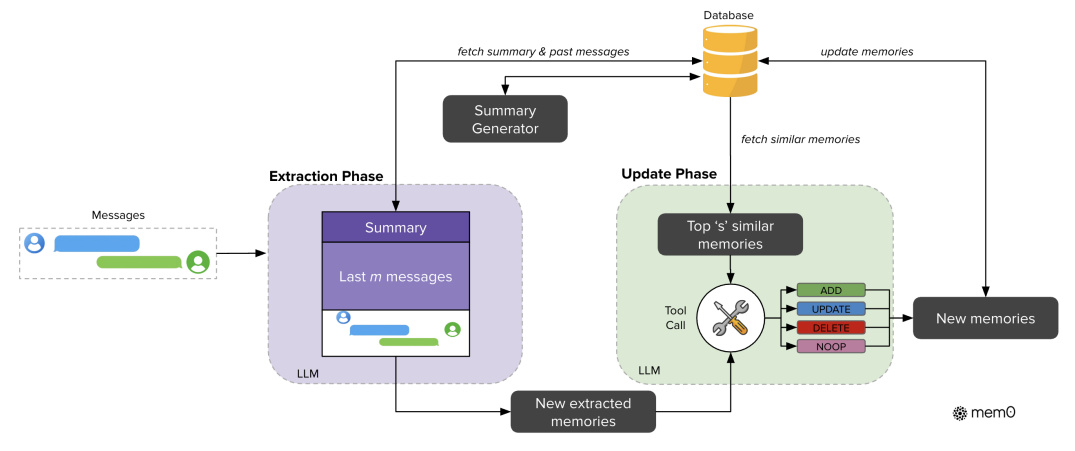 基础架构:Mem0(动态文本记忆)
Mem0 通过 “提取 - 更新” 两阶段 pipeline 动态管理对话记忆,核心是以自然语言形式存储关键事实,避免冗余并维持一致性。
基础架构:Mem0(动态文本记忆)
Mem0 通过 “提取 - 更新” 两阶段 pipeline 动态管理对话记忆,核心是以自然语言形式存储关键事实,避免冗余并维持一致性。
提取阶段:获取关键记忆
输入:新对话对 ((m_{t-1}, m_t))(用户 - 助手交互单元);
上下文来源:① 对话全局摘要 S(由异步摘要生成模块定期更新,确保全局语义);② 近期消息序列 ({m_{t-m}, ..., m_{t-2}})((m=10) 为超参数,提供细粒度时序信息);
输出:通过 LLM(GPT-4o-mini)提取的候选记忆集合 (\Omega = {\omega_1, ..., \omega_n})(仅保留对话中的关键事实,如用户偏好、事件时间)。
更新阶段:维护记忆一致性对每个候选记忆 (\omega_i),通过向量数据库检索Top 10 语义相似的现有记忆,再通过 LLM 判断执行 4 种操作:
ADD:无相似记忆时新增;
UPDATE:候选记忆包含更多信息时,更新现有记忆;
DELETE:候选记忆与现有记忆矛盾时,删除旧记忆;
NOOP:候选记忆已存在或无关,不操作。
核心优势轻量:
平均仅需 7K tokens / 对话(远低于原始对话的 26K tokens);
低延迟:检索时仅调用关键记忆,避免全上下文处理;
自一致性:通过 LLM 判断记忆冲突,确保事实准确性。
增强架构 Mem0g(图结构记忆)Mem0g 在 Mem0 基础上引入知识图谱,核心是用实体 - 关系模型捕捉复杂关联,提升多跳推理、时间序列推理能力。
记忆表示:有向标签图 (G=(V, E, L))
节点 V:实体(如 “Alice”“San Francisco”),包含 “实体类型(Person/City)+ 语义嵌入 + 创建时间戳”;
边 E:实体间关系(如 “lives_in”“prefers”),以三元组 ((v_s, r, v_d)) 存储(源实体 - 关系 - 目标实体);
标签 L:节点的语义类型(如 “Alice→Person”)。
关键流程
提取:两阶段 LLM 处理 ——① 实体提取器识别对话中的关键实体;② 关系生成器分析实体上下文,生成关系三元组(如 “Alice→prefers→vegetarian food”);
更新:通过相似度阈值(t)判断实体是否已存在,新增 / 复用节点后建立关系;对冲突关系,标记为 “无效” 而非物理删除,支持时序推理;
检索:双策略 ——① 实体中心检索(从查询中的实体节点出发,遍历出入边构建相关子图);② 语义三元组检索(将查询嵌入与所有三元组匹配,返回高相关结果)。
核心优势强关系建模:
擅长处理多跳、时间相关查询(如 “Alice 去年去夏威夷时买了什么?”);
可解释性:图谱结构清晰展示实体关联,便于追溯记忆来源。
这是一篇技术报告,Mem0 和 A-Mem 确实有很多相似点,细节上不太一样,代码就不细究了。